
API Versioning Has No "Right Way"

API versioning is a really difficult topic, and sometimes seen as a merely
religious debate. It’s done differently at different companies, and different
teams within different companies often vary.
Some folks move from approach A to approach B, and when approach B solves their
specific issues they act like approach B is "best" and nobody should ever use
approach A. That’s all well and good until they realize approach C might be a
good idea.
There are so many approaches to versioning that it can be hard to talk
about — let alone understand — them all, but I’m going to attempt to create a
definitive guide.
At work I am tasked with recommending one approach to API versioning, because
right now we have a mixture of approaches, and we’re using a few subtle variants
of the worst possible approach. My recommendations and research are being
converted to a guide for all of y’all.
Global URI Versioning
Versioning the entire API.
Usually in the path (e.g., /api/v1/companies), this could be a subdomain
(e.g., api-v2.foo.com/companies). If functionality was required that forced
the API to change the representation of companies drastically, a new version of
the entire API would be created, even if users did not change at all.
Usually these are planned timed releases, where — for example — a v2 of the iOS
app and v2 of the API were timed deployments, and v1 probably has a sunset date.
The downside here is that rarely are changes communicated clearly. In our
example, when the users had not changed, client developers have a rough time
confirming that. Also, it’s very common for smaller breaking changes to sneak
in, because "It’s a major release, that’s time to change stuff". With that
mindset, it’s very easy for API developers to shove in breaking changes that may
not be communicated or documented particularly well.
Some companies avoid this by being honest about the situation, and just make
entirely new API applications, on new servers, with new domains. They build
http://new-api.example.com, or use codenames,
then ditch the old. Eventually they’ll blackhole the old DNS once the old
version has hit acceptable low or zero usage.
This has the benefit of eradicating legacy as you go, but regardless of using
names, version numbers, or anything else, building out multiple APIs and forcing
the clients to consistently develop against new version after new version is
the most time consuming approach to versioning, for not just the API
developers but the client developers too. Everyone has to test everything on
each new upgrade, and this all takes forever.
Resource Versioning (URI-based)
Versioning specific resources by theirselves.
In the same example of /api/v1/companies and /api/v1/users, if companies
changed substantially then maybe a /api/v2/companies is created, but
/api/v1/users remains untouched. This makes upgrades easier for clients as
they know where to focus their attention. If there is no v2 for users, they just
keep on using the v1.
One problem with this approach is it looks nearly identical to global versioning
on the outside, and isn’t.
I’ve seen apps built with API::V1::BaseController, API::V2::BaseController,
and API::V3::BaseController, each of which have their own error format. That
would be entirely fine in global versioning, as the assumption is a client will
use all of v1, all of v2, or all of v3. In resource versioning a client might
hit a selection of v1, v2 and v3 endpoints at any time, and that means they need
to support three different error formats.
One end-user application was producing errors like Error: [object Object] to
actual end users, because the JavaScript code was expecting the v2 format { "error" : "some message" }, but a v3 error of { "error" : { "message" :"something", "code" :"err-123" } } has come back.
We could counter this specific issue with the use of a standard error response
across all systems (shout-out to RFC 7807 Problem Details for HTTP
APIs), but that is just fixing one
symptom of a larger problem.
Resource Versioning (Mime-Based)
This approach is very similar, but instead of versioning in the URL, versions go
in the Accept and Content-Type headers.
GET /api/companies
Accept: application/vnd.acme.companies.v2+json
The keeps the URL issue out of the way, and avoids API developers mistakenly
sharing conventions in version specific base controllers. This is what many
considered for a long time to be the height of API versioning (myself included),
and was the approach used by GitHub for a long time.
It keeps the same endpoint working for a long time, but if the header is
optional it can cause confusion. If clients don’t request a specific version,
should they get the earliest supported version, or the latest?
If v3 is added and v2 is eventually deprecated, clients would rather suddenly
start getting a whole new version which might break their apps.
Resource versioning does help, but can still be voodoo magic to many.
Method-based Versioning (URI-based)
Versioning by combination of URI and HTTP method.
I have only ever seen this one approach used at WeWork, but I’m sure it’s been
done elsewhere. It’s a variant of "Resource Versioning (URI-based)", which
basically does not version an entire resource, only the method for that
resource.
That’s hard to wrap your head around for a good reason. Let’s see how it might
work:
The latest "fetch all" for companies might beGET /api/v2/companies, but to
create a company you might POST /api/v3/companies, even though GET/api/v3/companies does not exist. The resource is not even guaranteed to match
on the same method, as method + URI is what makes it unique, so GET/api/v1/companies/{id} might be the best way to grab a single resource, and who
knows if those serializers are the same.
This has all of the cons of the previously mentioned solutions, with a few more
thrown in.
Primarily, that API developers get used to disposable endpoints. Every time
Client B needs to update a resource, they create their own new method, ignore
the existing one, and this is tolerated as normal due to a lack of API
versioning strategy.
Disposable endpoint thinking has lead to situations where new update methods
have been created that only contain subset of earlier update method
functionality. The API developer adding functionality was unaware of the
functionality in previous versions, and didn’t worry about looking
because "nobody ever upgrades anyway."
Due to this divergence, even if a client wanted to upgrade, they could not!
They are trapped on older versions, which then have to be supported forever, for
fear of breaking the clients using the newer endpoint.
This increased functionality is essentially asking all API teams to support more
functionality than they should, and that is time and money that could be spent
on more useful things.
API Evolution
API Evolution is the concept of never breaking your contracts until you
absolutely absolutely have to, then when you do you manage that change with
sensible warnings to clients. It is not about making arbitrary changes and
breaking stuff.
Generally you add new fields, or add a new resource, and if you absolutely must
you can deprecate and eventually remove the old bits when it’s no longer being
used.
This is an approach currently being popularized by GraphQL, but one that REST
advocates have been talking about for decades. A great writeup on HTTP
Evolution was done
back in 2012, and more recently an excellent post on API Change
Management.
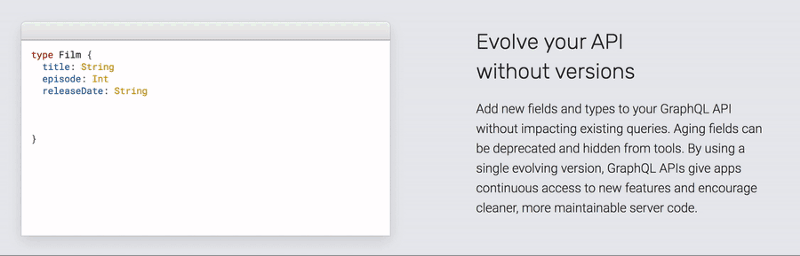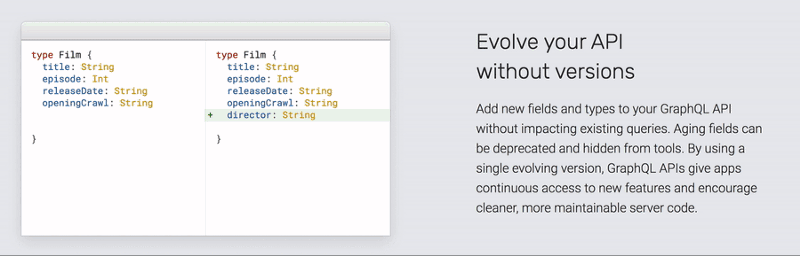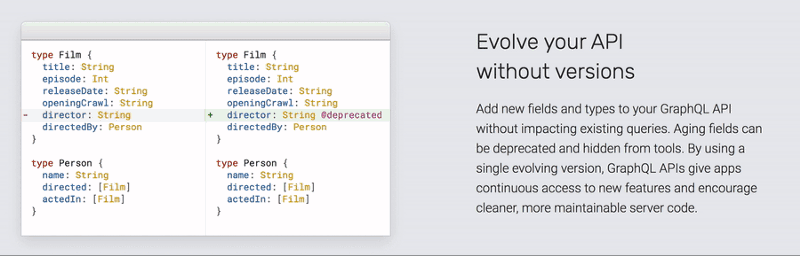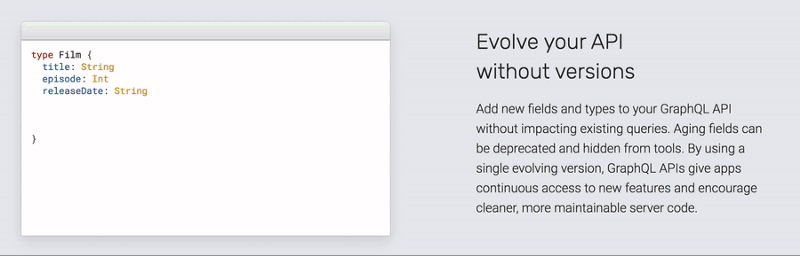
Evolution is not a GraphQL feature, but a concept that works rather well in most types of API.
At a previous company offering crowdsourced
carpooling,
we only added fields, never removed them. This was fine for the majority of
changes, but when backwards compatible issues absolutely could not at all be
avoided, we took advantage of the fact that a business name for a concept had
changed, and took the chance to make our API match the business name.
Matches were a relationship between a driver and a passenger, and multiple
matches would make up the carpool. The BC change was to add multiple drivers,
which completely screwed the concept of matches. When we switched from
/matches to /riders, we changed the JSON representation entirely, but
internally those two representations shared the same code.
After a few months, the matches concept was deprecated, and clients started
using the new riders concept. The internals changed multiple times as we worked
on recoding towards the new goal, and we converted matches to riders, then
eventually matches was just a different serializer sat on top of riders. During
this process the contract never changed.
We went through a few backflips to make that happen, but our clients didn’t need
to do a thing, other than switch to "riders" in their own time. Android and iOS
apps launched independently, and that didn’t matter for us at all.
The approach of evolution pushes some extra work onto the API development team,
but avoids a similar amount of work being pushed onto the client teams. If one
API has 5 clients, then we’re saving 5x the development, testing, etc.
Deprecations Are Tricky
Whether you use Global URI Versioning, or want to use Evolution, you are going
to need to consider how you handle deprecations.
If your team is small enough, you can just email the iOS developer and suggest
they use the newer endpoint, or the newer whole damn API, but if you work at a
company with hundreds of developers (and 30+ services!) this might not be a
successful approach.
There are a few approaches to handling deprecations which you can use right now.
Deprecating Endpoints with Sunset
At WeWork we built a Faraday wrapper (popular Ruby HTTP client) called
we-call
that forces some good conventions onto client and server alike, using the power
of middleware.
One of those conventions is syntactic sugar around using the still-in-draft
Sunset header, using
annotations to make it super easy. You don’t need to use the whole we-call gem,
you can just use
faraday-sunset, or if you’re
using PHP you can use
guzzle-sunset.
Deprecating Fields with OpenAPI v3.0
You can advertise to humans that fields are going away with OpenAPI and it’s
"deprecated" keyword,
added in v3.0. This is far from perfect as there is not really a computery way
to detect these deprecations without shoving a link to your OpenAPI schemas into
the JSON response.
JSON Schema is working on adding
this, and it’s
far more common for JSON Schema links to be placed into the JSON response. For
now, don’t remove any fields, just add new fields, and use a new representation
if you really just cannot handle the old contract.
Update 19th May, 2019: JSON Schema got a deprecated keyword to match OpenAPI v3.0.
PayPal do
this
for their APIs, but they’re using vendor extensions that pre-date OpenAPI’s
deprecated functionality.
Using Migrations a’la Stripe
Stripe have outlined an approach to making their public API
evolvable, which is way above and
beyond. Instead of using HTTP / in-band metadata to advertise the fact that it’s
going away, they build out migrations which translate older requests into newer
ones internally.
They keep things backwards compatible for a certain amount of time before
destroying the migration, emailing the client developers a whole bunch about the
change before that point.
This was done by Facebook for years, before they threw everything in and went
with global versioning in the path…
Be Honest About Building RPC APIs
Most URI-based versioning is thinly veiled RPC, that just look a bit RESTish.
If companies doing URI-based versioning using RPC naming conventions, the APIs
would look a bit more like this:
GET /api/v2/userswould beGET /GetAllUsers(without pagination for some
client that nobody remembers)GET /api/v3/userswould beGET /GetAllUsersPaginated(if you want pagination just use this one!)GET /api/v2/users/123would beGET /GetUserAppAGET /api/v2/users/123/simplewould beGET /GetUsersAppBPATCH /api/v2/companieswould bePOST /UpdateCompanyFromAppYPATCH /api/v3/companieswould bePOST /UpdateCompanyFromAppZ
If people are going to design their APIs as RPC with a RESTish facade, they
should just commit to being an RPC API and build endpoint for specific clients
like they’re literally already doing.
Just be honest about it. Hide the false intention, RPC the lot, document as
such, and maybe just use gRPC.
Summary
API Evolution is incredibly powerful if you put in the work to make it possible.
A commitment to
contracts
will make things easier, especially with JSON Schema bringing deprecated in the
future.
Global URI Versioning is the least awful alternative. I would only recommend
this to teams who cannot commit to contracts, and build incredibly different
APIs to match incredibly different iterations of applications (e.g., v1, v2, v3
of a mobile app). Maybe just use codenames for each version and delete the old
APIs, instead of trying to jam it all into one codebase and potentially taint
one version with changes to some shared code in another version.
Either way, global versioning is literally not at all RESTful, and hints towards
RPC, and that’s coming straight from Roy.
Resource-based content-negotiation is ok if you’ve got some very HTTP-savvy
clients and document your intentions incredibly well, but it’s essentially a
shortcut to kinda evolution, which doesn’t really add any benefit.
And for the love of The Flying Spaghetti Monster, please don’t ever do any form
of method-based versioning. It never makes any sense. You’re making things
terrible for everyone, splitting expectations, creating overhead, and focusing
on short-term gains and long-term confusion.
However you decide to version, so long as you’re using one of the few more
sensible approaches, remember that it’s not about deciding which is "best". It’s
about sharing and understanding the pros and cons of various approaches, and the
priority is educated decisions based on that information.



