
How to Capture Quite a Lot of API Traffic
When rewriting an API, it's critical to make sure you don't change the shape of your inputs and outputs unexpectedly. After all, API specs are called contracts for a reason. This article outlines an approach to capturing API traffic using Optic for just this purpose.


When I'm rewriting an API, I want to make sure I'm not unintentionally changing loads of stuff. After all, API specs are called contracts for a reason. To do this, my favorite new approach is using Optic to capture HTTP traffic, so we have an OpenAPI to work against. We can then "contract test" against that OpenAPI as the new API is built, and be alerted immediately if anything mismatches.

Some APIs a pretty "static" in what they return. Most responses look the same, so you can just capture a few responses and call it a day. however some APIs are more "variable" in what they return, so you want to get a good amount of traffic running through Optic to make sure you're not missing any of the possible variations.
So here's what I am doing right now, writing this whilst a huge bash script runs through 45,000 odd HTTP calls.
First, they've got an Airtable database they're trying to escape, so I've made a view on there which shows me aaaaaaaall of the UUIDs for the endpoint I'm most concerned about.
Airtable let me copy and paste 45,000 UUIDs out, and I've dumped them into VS Code.
Using the multi-cursor feature (CMD + Shift + I) I have changed this pile of UUIDs into a list of bash commands using httpie (because nobody has time to remember how curl works), turning off SSL verification and sending it via the Optic Proxy which is running from optic oas capture openapi.yaml https://api.example.com.
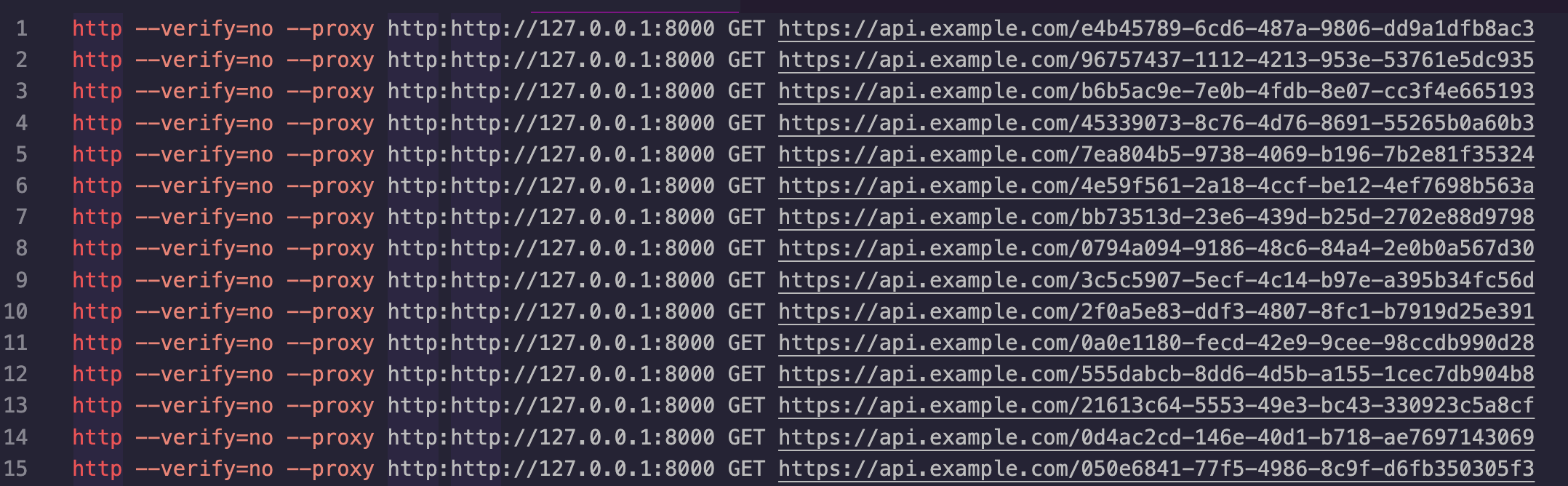
VS Code got a bit upset about 45,000 lines, and decided to only let me work on 10,000 at a time, which is fine. I popped an exit in there and saved the Untitled file as a bash script called import.sh.
Now I can crack open a new terminal window and run ./import.sh.
The bash scrip then runs through the first 10,000 requests quite happily, and I can delete those lines and pop an exit below the next 10,000.
I also could probably have turned that untitled file full of UUIDs into a JavaScript array and run it through node doing fetch() calls, but this has worked out fine. You do you.
When I have finished capturing requests, I use the verify command:
optic oas verify openapi.yaml
That shows me what its found, and I can update the openapi.ymal with either all of the endpoints, or just some. I only hit one endpoint so this doesn't matter.
optic update openapi.yaml --all
Job done! From there I can upload it to Optic for quick "this is what it looks like", shove openapi.yaml into git to use for development, or plop the file into the project management software for some other developers to pick up as they work on the new functionality.
This might all seem like a bit of a faff, but it gives me an openapi.yaml that I can be confident accurately represents the old API, because I have put the entire API through it, contract testing in development, then using it as documentation when I'm done to avoid having to do that far more boring extra work later.
Give it a try. Did it make better or worse OpenAPI than you did by hand? Answer in the comments!



