
Creating OpenAPI from HTTP Traffic


Around this time of year we're thinking about things we're going to do differently, new practices we've been putting off for too long, and mistakes we want to avoid continuing into another year. For many of us in the API world, that is going to be switching to API Design-first, using standards like OpenAPI to plan and prototype the API long before any code is written.
More organizations are switching to API Design-first with OpenAPI, thanks to huge efforts from tooling vendors - from the bigger folks: Stoplight and Postman, to the smaller open-source OpenAPI tools - making it far easier to do.
Sadly, there's an awkward position many of us are stuck in. We have an API that we built years ago, and now our DevRel team want OpenAPI-based API Reference documentation, the API governance team want OpenAPI to be included in the pull request for any code change, the testing team want our OpenAPI to set up end-to-end contract testing, but we don't have any OpenAPI... AGH!
We wrote before about some slightly hacky ways to create OpenAPI from things like Postman Collections, using JSON to JSON Schema converters, and a whole lot of mucking about, but thankfully these days there are far nicer solutions around. One especially smooth tool is Akita!
Akita is an observability tool, which can sniff HTTP traffic, and build models of your data. Once it's done that, it can create a graph of all your APIs to give insight into a system, intelligently catch and communicate breaking changes, and various other handy things.
We're going to use just part of it's power to create OpenAPI for an API after it's already been deployed to production, so that we can use API Design-first for any new functionality going forwards.
Looking for a example wasn't hard. I'd made this mistake myself earlier in the year. We rushed an API for Protect Earth. There was no need to design the API because it had to match a contract defined by an existing tree-planting partner, so we just copied some of their JSON, and coded to that rough shape hoping for the best. Of course this rush blew up in our face immediately. The first consumer integration was a lot of awful trial-and-error which took ages, and when the second consumer they didn't have any documentation. I know I know. The mechanic’s car is always broken...
So let's get on with it. We could install the Akita Client anywhere, maybe pop it on a staging/production servers to detect that traffic, but installing on a laptop is easier for this workflow: running a proxy, sniffing requests/responses for https://api.protect.earth/, and importing into Akita. This is documented nicely on Akita's docs site, but lets focus on the specific bits for this workflow.
Step 1: Setup Akita Client locally
Head over to akitasoftware.com and click Join Beta. Maybe it's already out so click Register, just get yourself an account somehow.
Now we can install the akita-cli client. On macOS that'll be a brew install, and for everything else theres docs.
brew tap akitasoftware/akita && brew install akita-cli
When that's installed, use the akita login command to log in. You'll want to go fishing for your API Key which is in Settings on the Akita dashboard.
akita login
API Key ID: apk_0000000000000000000000
API Key Secret: ******************************
Login successful!
API keys stored in ${HOME}/.akita/credentials.yaml
Step 2: Man in the Middle Proxy
In order to intercept the HTTP traffic going to an encrypted website (https://) we can use the free tool mitmproxy, which is another brew install.
brew install mitmproxy
Then, we'll want to grab the har_dump.py script from mitmproxy which will turn intercepted traffic on their proxy into a HAR (HTTP Archive format) file.
wget https://raw.githubusercontent.com/mitmproxy/mitmproxy/master/examples/contrib/har_dump.py
Ready for action.
Step 3: Using the proxy
In one terminal session, run the proxy server with the har_dump.py script loaded up, and dump.har set so the HAR file will be saved locally.
mitmdump -s ./har_dump.py --set hardump=./dump.har
If it's working, the proxy will run on localhost:8080 so you can use that as a proxy in whatever http client.
Maybe you're one of those folks who can remember how curl works.
curl -D - -k --proxy localhost:8080 https://api.protect.earth/v1/orders/c36916f7-7591-47e5-b069-f983b9c0f320
That will make requests to the https://api.protect.earth/v1/orders/{uuid} endpoint of the Protect Earth API, pass the request and response through mitmproxy, and write the output to dump.har.
Doing all of this in curl was a bit of a mess so I grabbed Insomnia and clicked around the API a bit, hitting as many resources and collections as possible, so the OpenAPI is based on a superset of all the data it's seen, instead of just the one JSON representation.
Step 4: Converting HAR to OpenAPI
There are a lot of tools out there to convert a HAR to OpenAPI, but some of them are old, some of them are bad, and most of them are both.
Akita is fantastic at doing this, and can handle all nullable, optional, polymorphic, and generally funny shaped data! It'll take a stab at noticing formats of strings, all of which saves you time from filling all this in manually.
The akita apispec command can import dump.har to your service, and give it a name. The service was protect-earth and the spec was just called mySpec because that's what the docs said and it doesn't seem to matter.
akita apispec --traces dump.har --out akita://protect-earth:spec:mySpec
The Services page in Akita should now be aware of the service you just uploaded.
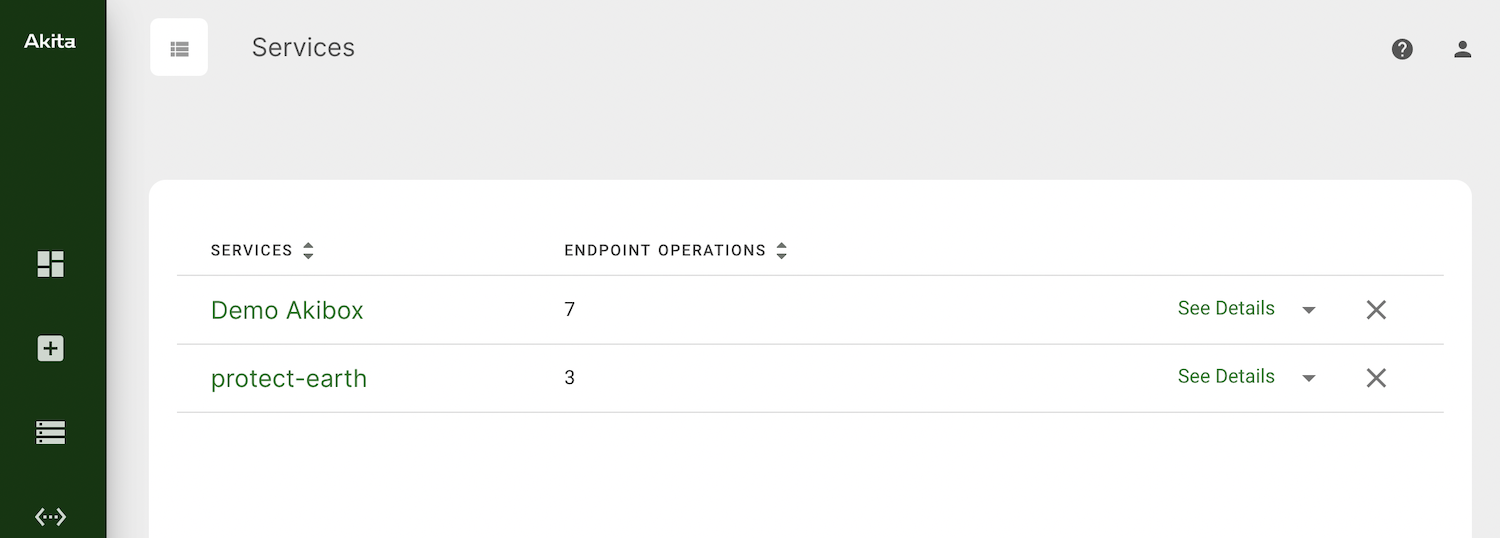
Click on that and there will be a list of endpoints its aware of, with parameters used to avoid duplicating endpoints for different UUIDs or other parameters as other tools often do.
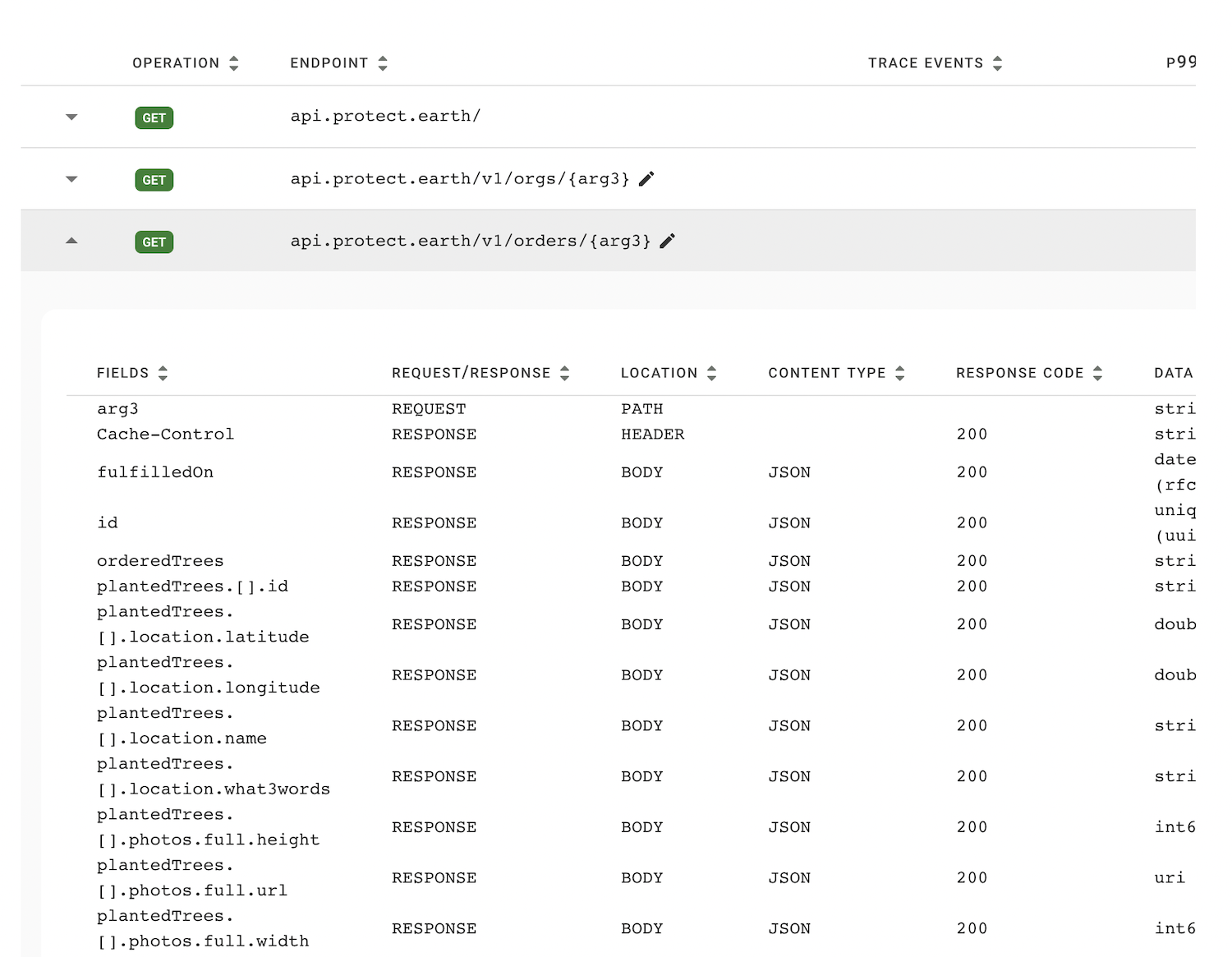
Those endpoints have all their metadata associated in Akita, which means it's ready for exporting as OpenAPI through the web interface.
The OpenAPI document will be created as YAML, and at time of writing is producing OpenAPI v3.0. Ideally it would soon be updated to OpenAPI v3.1, but the differences are not huge and can be changed manually.
Once you've got this OpenAPI YAML document you can shove it into your Git repo to live alongside your code. It might not be perfect, but you can hook that Git repo up to a web-based OpenAPI editor like Stoplight Platform, or a local file editor like Stoplight Studio, or just manually wrangle the YAML in your favourite text editor.
However you go about it, you can tidy up the OpenAPI document according to your preferences, and publish the docs when you're done.
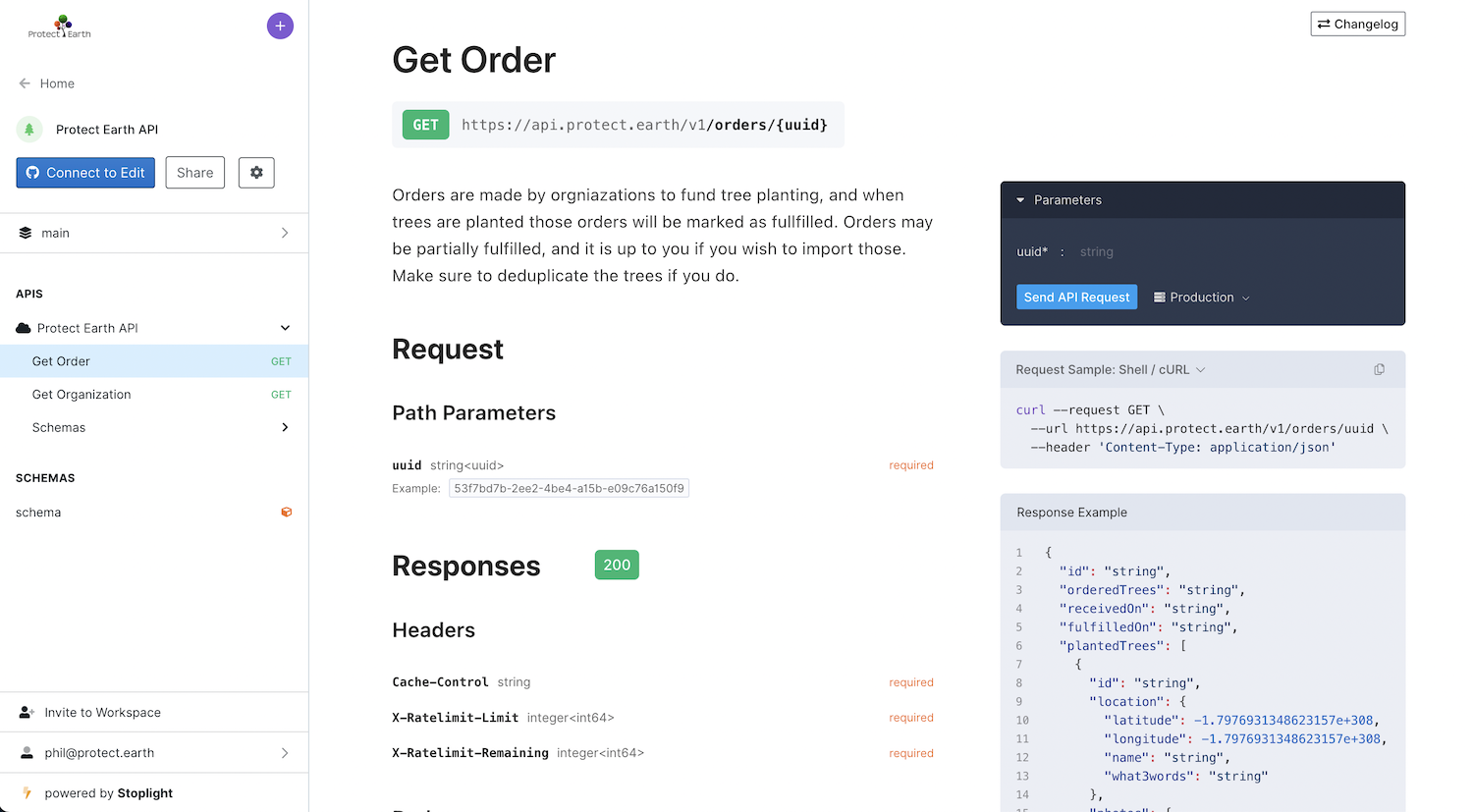
How you might chose to tidy up the OpenAPI is another article for another day, but getting some OpenAPI without having to manually wrangle it all by hand is a huge timesaver. More importantly it's likely to help API teams get on board with any organization-wide push for API Design-first, or any other API Program or workflow that requires OpenAPI.
Now, I'm off to plan out a new endpoint for the Protect Earth API using the design-first approach, so I can give multiple consumers a mock endpoint to hit to see if it'll work for them, before I bother writing up a bunch of code I'll only have to change later based on their feedback.



