HTTP Caching APIs with Laravel and Vapor
Stop wasting server(less) resources answering the same questions over and over again, by enabling CloudFront for your Laravel REST/HTTP API.


Laravel Vapor is a serverless hosting solution tailored to Laravel PHP applications, which sits on top of Amazon Web Service. Severless can be a great solution for HTTP/REST APIs which do not want to waste server resources when nobody is asking any questions, but when people are asking the same questions the serverless approach is still wasting resources rewarming the Lambda, flailing around in a mess of PHP and SQL calls serving up those answers over and over again for no reason. HTTP network caching is the solution to this problem, and it's simply a case of turning it on.
There are many solutions for HTTP network caching, both self-hosted solutions like Varnish and Squid, or SaaS solutions like Fastly and Cloudflare Cache. We don't need to pull in any of these solutions because Laravel Vapor already utilizes AWS API Gateway, which like most API gateways has it's own network caching solutions built in.
Despite Laravel Vapor making most everything incredibly easy, nowhere in the web UI or YAML-based config is there an option to turn HTTP network on, so we're going to have to roll our sleeves up and do it ourselves.
It's worth the work, because it cuts down on costs, and even helps reduce the carbon impact of your software, so it's basically rude not to turn it on.
What is HTTP caching?
HTTP caching tells API clients like browsers, mobile apps, or other backend systems if they need to ask for the same data over and over again, or if they can use data they already have. This is done with HTTP headers on responses that tell the client how long they can "hold onto" that response, or how to check if it's still valid.
When HTTP cache servers (reverse proxies) are involved, it goes up a level, making sure that even if clients are not bothering to do the caching, that the API's application server is not being pestered if a cached response could be used. There are infinite ways to handle this, but with the proliferation of Content Delivery Networks (CDNs), it's now easier than ever to pop a cache proxy between the client and the server, storing responses for reuse whenever possible.
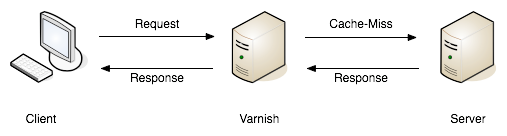
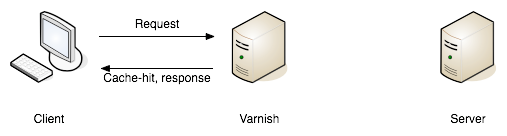
This works very differently from server-side caching tools like Redis or Memcached, which always involve the HTTP connection coming into the web server, but then help the application short circuit querying the database or something else that was too slow to do every time. This is still web traffic to the application servers, but they will answer those repeatitive requests a bit quicker. HTTP caching instead helps negative the request ever being made (client caching), or avoids it reaching the web server (network caching).
In a serverless environment it can really help to have a CDN caching at the network level, because the serverless approach pays per request. Utilizing HTTP caching means reducing traffic, reducing how many times that Lambda needs to spin up, and by reducing the number of responses that need to be generated by the server which is also going to reduce bandwidth costs.
There's a more to learn about how exactly HTTP caching works for APIs and how to design your APIs to be more cacheable, so check out our recent guide for API Design Basics: Caching to learn more about that. This guide is going to focus on enabling it for Laravel applications hosted on Laravel Vapor.
Network Caching with AWS Gateway + CloudFront
AWS has a CDN called CloudFront, and it works nicely with AWS API Gateway, both of which are already spun up by Vapor so let's just get them talking to each other. Using CloudFront might sound a little odd at first, as CDNs like CloudFront are generally more associated with caching images, CSS, and JS for frontend applications, but there is absolutely no difference in caching JS, CSS, and images, as there is to caching a REST/HTTP API.
Everything in a REST API is considered a resource, much like all the images and other assets are considered resources. Any of them could change over time, and then those multiple resource versions are floating around for a while, with the server defines rules about how stale is acceptable based on the particulars for that resource.
Far too many API developers are scared of utilizing HTTP caching, and this fear of the unknown is wasting money and natural resources for no reason. There are plenty of ways to handle validation (fetching latest information only if it changed) and invalidation (purging the CDN in extreme scenarios) so there's no reason to fear it. Soldier on.
Once caching is enabled at the network level, we can add caching logic to the Laravel Framework with the caching middleware, and this will automatically cover caching GET and HEAD requests using the standard Cache-Control and ETag headers so we don't have to think about it.
Step 1. Upgrade to AWS API Gateway v2
First of all the best thing to do is upgrade to the latest version of the AWS API Gateway. AWS API Gateway v2 is cheaper and faster, so it's a good idea to upgrade even if you get bored and forget to continue with the rest of this guide.
Edit the vapor.yml file to add the gateway-version: 2 line.
name: tree-tracker-api
environments:
production:
domain: api.protect.earth
gateway-version: 2
If Vapor is set up to handle DNS automatically this is as a simple case of pushing/deploying changes, and everything will take care of itself. A new API will appear and your Vapor application will soon be utilizing it.
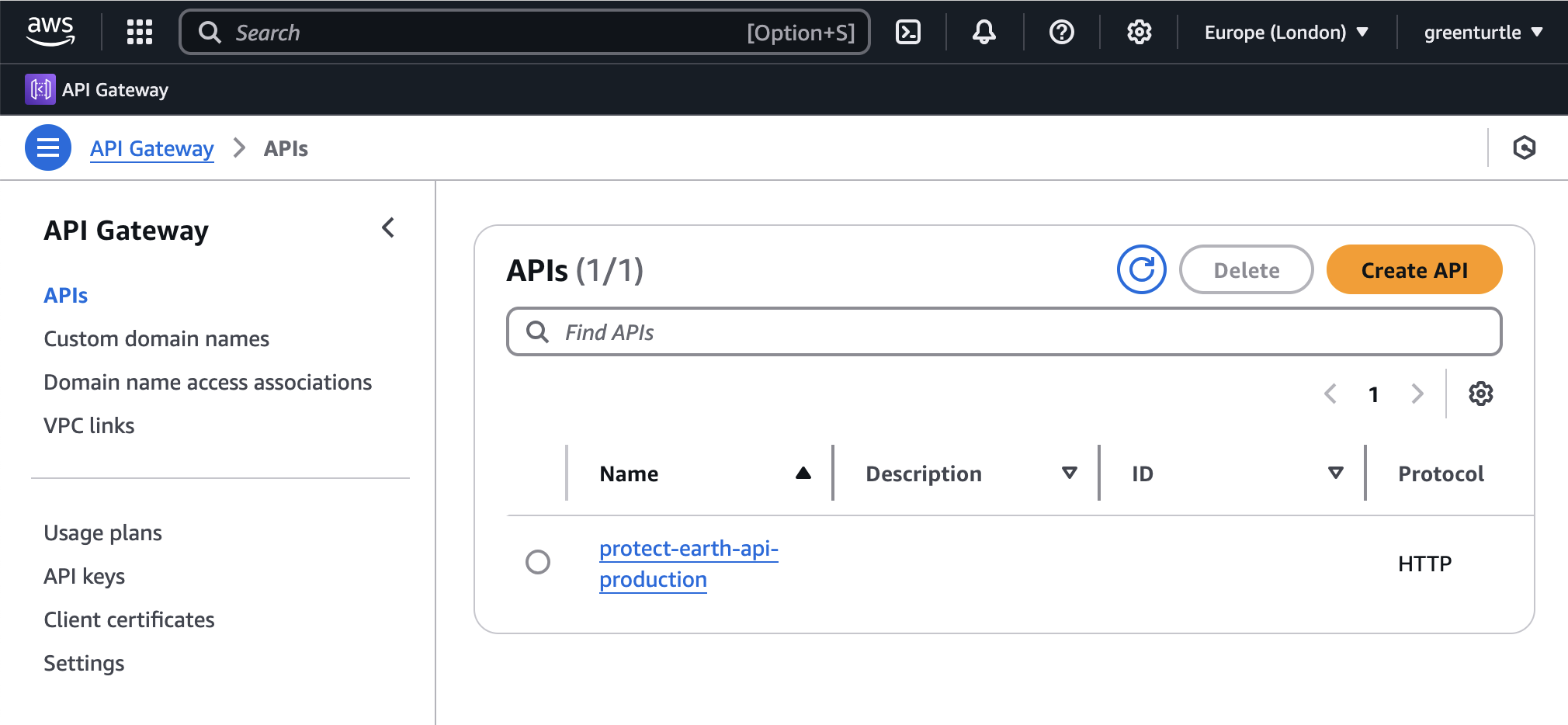
Those of you managing DNS manually will need to deploy this change to see the new CNAME details in the Laravel Vapor UI, but you might as well hold off until the next step or things will need to be changed again.
Step 2: Slide CloudFront in front of API Gateway
Pop over to the CloudFront section of the AWS panel, and create a new distribution pointing to the AWS Gateway for the application.
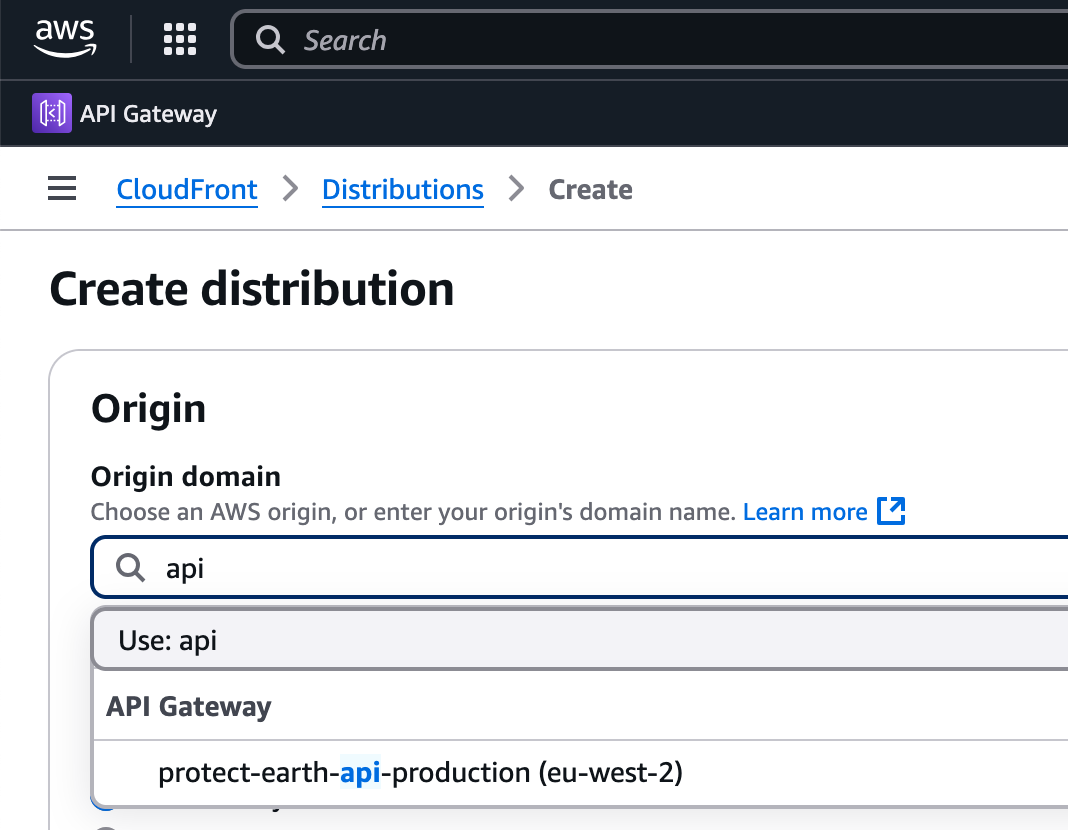
Set the DNS alias as whichever domain/subdomain you intend on using. For me its api.protect.earth as the main protect.earth site is, for now, using SquareSpace (🤮).
Under Cache key and origin requests pick the recommended option. This will show a dropdown, and there the Cache Policy can be set to "CachingOptimized".
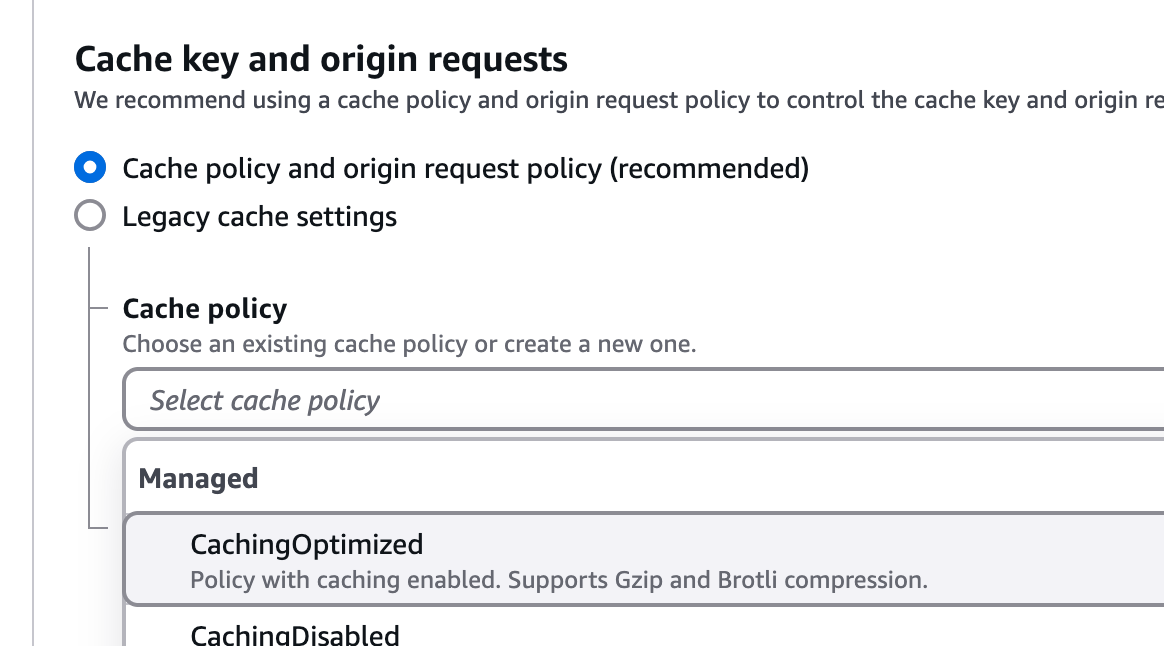
Enable "Origin Cache Headers" to respect Cache-Control settings from the API (more on this shortly).
When this distribution is created it will spend a little time spinning up, and as soon as its ready the distribution will display a subdomain like d1tpxxxxxxxx.cloudfront.net.
Use this to update the DNS for your API subdomain like api.protect.earth, or get more creative to proxy it off to a subdirectory like protect.earth/api. However you do it, the goal is to send all API traffic through CloudFront so that any caching headers the API emits will now be respected by the CDN at all various edge locations selected.
Step 3: Adding caching headers to the API
There are several ways to add cache headers.
One approach is to just shove out some headers directly onto the response in each controller, like so:
return response([])
->header('Cache-Control', 'public,max-age=86400');This will work for the most basic of things, but there is some automatic functionality being missed that will come in handy when we start using ETags or Last-Modified, so I would recommend invoking the built-in Illuminate\Http\Middleware\SetCacheHeaders middleware.
Make sure the following cache.headers alias is enabled in app/Http/Kernel.php.
# app/Http/Kernel.php
protected $middlewareAliases = [
'cache.headers' => \Illuminate\Http\Middleware\SetCacheHeaders::class,
];
This can then be applied to the entire "api" group, or added to each route indivudually, something a bit like this.
# routes/api.php
Route::get('/sites', App\Http\Controllers\Maps\SiteController::class)
->middleware('cache.headers:public;max_age=86400');
For data that's not likely to change often at all, you can really crank the expiry time up. For example, Protect Earth has tree planting projects at various "sites" and we're unlikely to rename a site too often if ever, trees are planted once ever and maybe a few more each winter or maybe none more are needed, and we're never going to move a field somewhere else so the coordinates aren't going to change. We really doesn't need to pretend like this is real-time data. Starting with a day long cache might be a reasonable first step, and it's easy to crank it up over time.
For other that might change more often, you can learn more about validation using ETags to increase the cachablity of changeable data.
I could not find any documentation for how this Laravel HTTP Caching middleware works, but seeing as it is a wrapper around Symfony HTTP Cache we can glean what we need from there. Here are the options.
'must_revalidate' => false,
'no_cache' => false,
'no_store' => false,
'no_transform' => false,
'public' => true,
'private' => false,
'proxy_revalidate' => false,
'max_age' => 600,
's_maxage' => 600,
'immutable' => true,
'last_modified' => new \DateTime(),
'etag' => 'abcdef'All of these terms and keywords derive their meaning from RFC 9111: Caching, so we can use combinations of these for specific situations.
Do not store response in any cache
If information is sensitive or could contain PII you want to avoid being saved in any proxy caches, browser caches, or anywhere at all, stick a no_store in there.
->middleware('cache.headers:no_store');Cache for five minutes to this user
Data doesn't need to be public, it could be constrained to the user as defined in the Authorization header. Another handy reason to use this for APIs instead of inventing contentions like My-Special-API-Key.
->middleware('cache.headers:private;max_age=300');This is never going to change
Some information simply will not change ever. If a document that is already versioned, like /files/abc123/versions/123456 and if it was edited then a new version would be created. In this case you can give it a huge max-age and pop an immutable on there to say "don't even bother trying to revalidate this, it wont be different".
->middleware('cache.headers:max_age=31536000,immutable');This might actually change
Sometimes you have a pretty sizeable response, and you know there's clients polling it for updates. For Protect Earth it's a list of orders for organizations, being polled every day to see if they've got any new trees planted. I ask them not to do this because sometimes we go months without planting any trees (planting season is October through April in UK) but still, they do, and the responses are huge.
We can use the following cache headers to set a weekly cache, because a week is soon enough, and then we pop the etag on there to make sure clients revalidate.
->middleware('cache.headers:max_age=6048000;etag');The built-in Laravel middleware will response with an ETag on each request, and when that ETag is sent back through the If-None-Match header by any cache-aware HTTP client, CloudFront will know exactly what to do with it. If there is an entry in the cache that matches this ETag value, it will respond with a 304 and no body.
http GET https://api.protect.earth/orgs/some-uuid -h 'If-None-Match: "9e9736203e9f15f11a4b263350561ea6"'
HTTP/1.1 304 Not Modified
Cache-Control: max-age=300, public
ETag: "9e9736203e9f15f11a4b263350561ea6"
X-Cache: Hit from cloudfrontThis is a hit, but the CDN knows the client application already has a response which it can reuse, instead of the CDN even bothering to emit that same massive JSON and waste resources. The API server did nothing, the CDN didn't do much, and the client is happy.
There's loads more we could go through, but that's quickly becoming a whole other article, so let's save that for another day.
Step 4: Add some tests
It's usually a good idea to pop some tests in to make sure the cache headers are coming out as expected, because there are so many different ways to apply those headers somebody might accidentally undo your work and nobody will notice until the server costs spike up over the month.
<?php
use App\Models\Certificate;
use App\Models\Unit;
describe('GET /certificates/{uuid}', function (): void {
it('declares a cache-control header on response', function (): void {
$certificate = Certificate::factory()
->hasUnit()
->create();
$this->get('/certificates/'.$certificate->uuid)
->assertHeader('cache-control', 'max-age=86400, public');
});
If these tests look a little alien, check out our guide on contract testing with Laravel and OpenAPI, then you can pop this test right in there next to those.

Step 5: Prod the API to see if it worked
First thing is to make sure our API is still up.
$ time http HEAD https://api.protect.earth/sites
> Cache-Control: max-age=86400, public
> X-Cache: Miss from cloudfront
> ...snip...
> 0.49s user 0.14s system 16% cpu 3.839 total
Great, 0.49 seconds, and the X-Cache shows it was a "miss". A miss means there was nothing in the cache able to serve the request, which is to be expected as we only just turned caching on a moment ago.
Trying to again should really speed things up.
$ time http GET https://api.protect.earth/sites
> Cache-Control: max-age=300, public
> X-Cache: Hit from cloudfront
> .. snip ...
> 0.29s user 0.10s system 44% cpu 0.891 total
Cache hit, which means something was found in the cache that met the requirements, and because this is a lot faster than pestering the origin web server the response is down from 0.49s to 0.29s. A decent improvement, especially as I'm doing this from an Alp with avalanches actively coming down around me and the whole village being on emergency power.
So with that working, let's learn how we can monitor how the API is doing beyond a quick poke.
Step 6: Monitor Hit Rates in AWS
All of the client applications now using the API are going through the network cache, so you can monitor how this is going through the AWS UI.
Go to the API CloudFront distribution and click Cache statistics. There you will be a breakdown of hits and misses over time.
The number of requests that hit or miss is known as the hit rate, and for every hit that's one less thing the API had to bother doing.
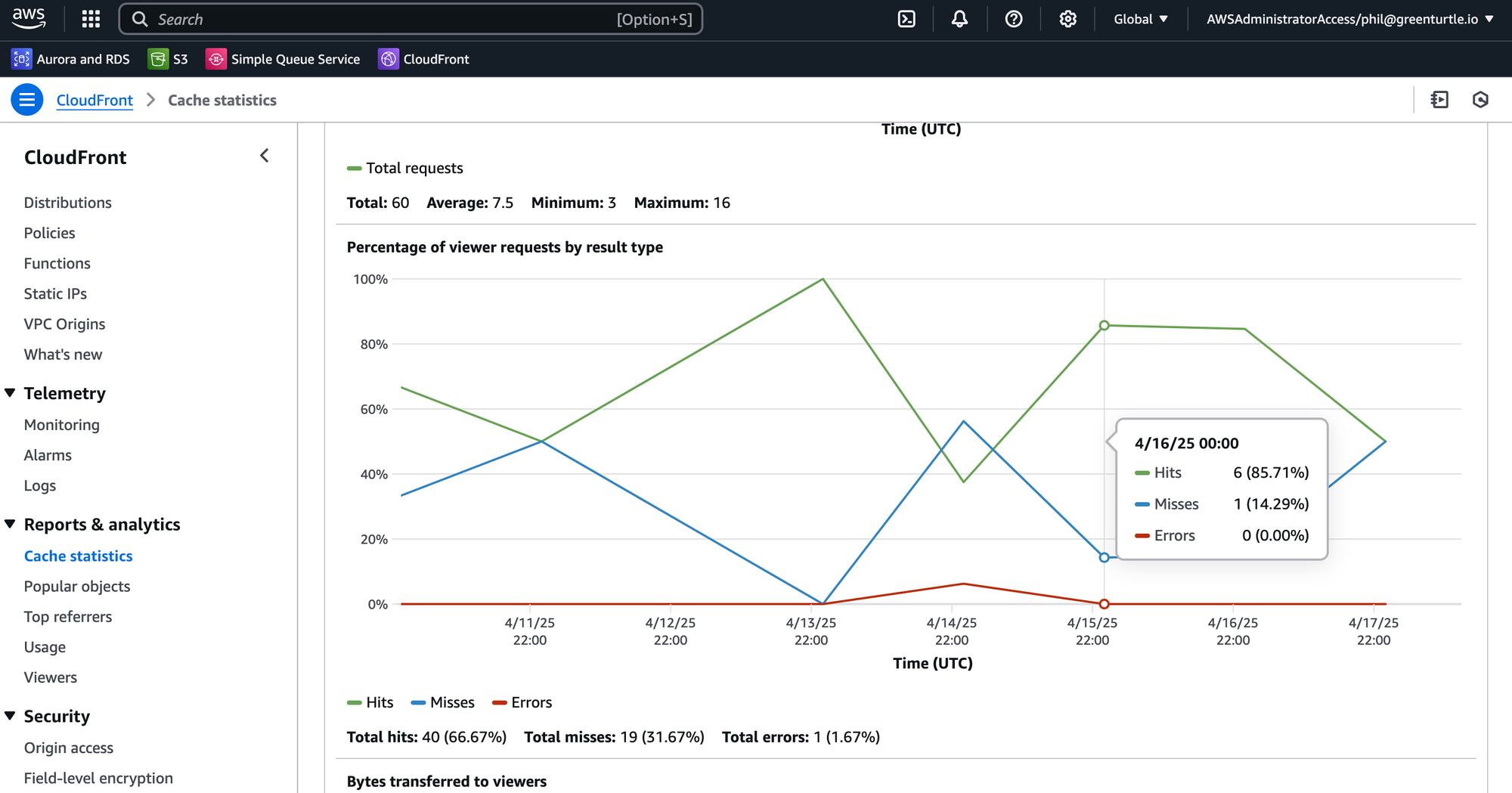
The size of the responses for a hit or miss is also interesting, because you can see how much data is not being generated slowly by your API but is instead being served quickly from the CloudFront cache.
CloudFront being in front of our API traffic does a few other useful things, like allowing us to see where our traffic is coming from.
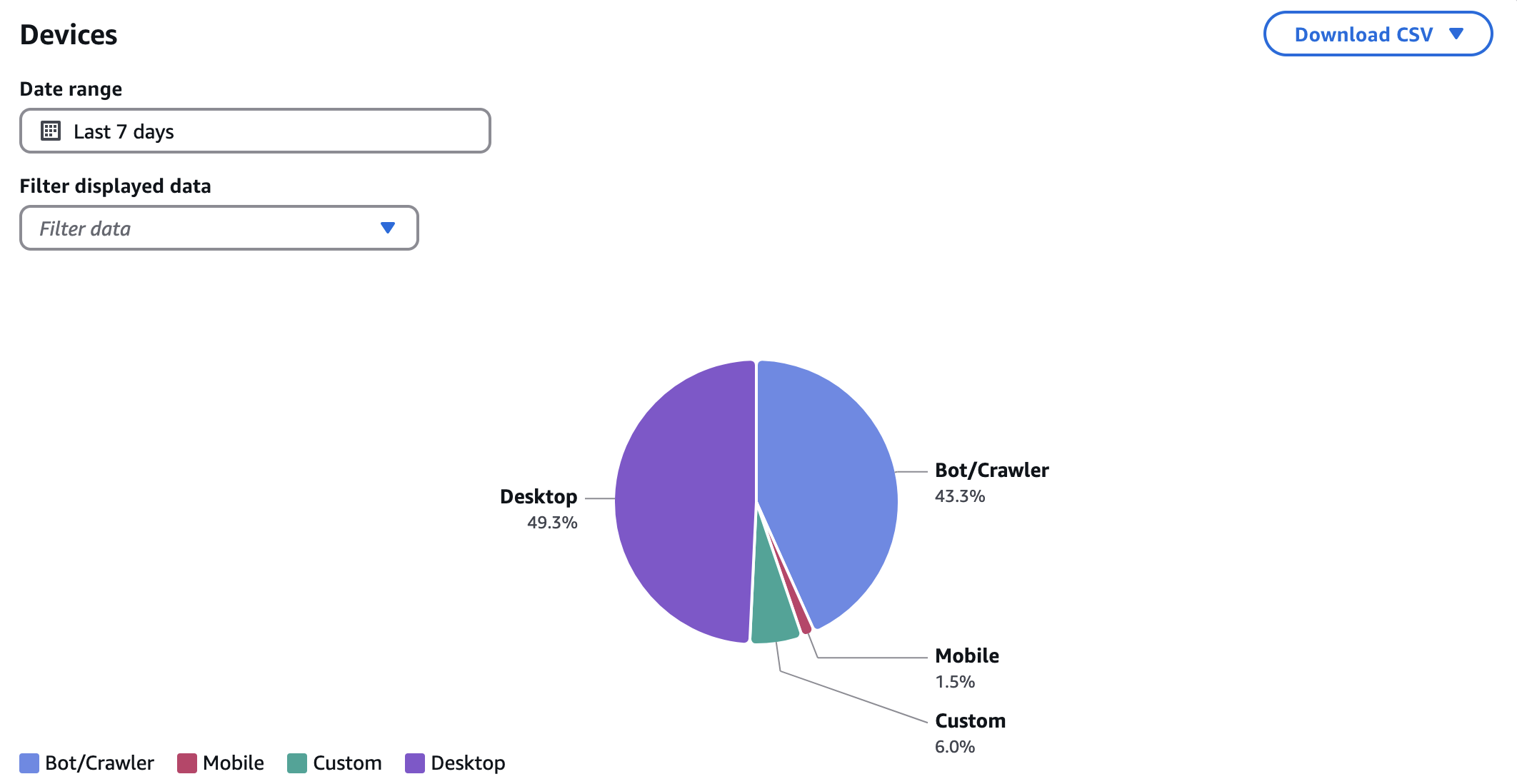
50% bots and crawlers seems like a lot. With our users optimized and loading information far more quickly, the next step in keeping our servers from stressing out for no reason will be to block crawlers and bots from messing with us, but that's yet another article for another day.
Take this and run
Dipping your toe into the world of API caching with a little bit of Cache-Control is a solid start, and learning more about ETags and the whole validation flow will help open the door to caching more documents which may change over time.
People often underestimate how much of their API could be cached, but it's worth digging into because reducing redundant requests will:
- Cut down on server load (lowering hosting costs).
- Reduce network traffic (lowering bandwidth fees).
- Minimize energy consumption (lowering environment impact).
Imagine millions of users no longer making unnecessary requests for unchanged data. Designing APIs to be cache-friendly from the start not only benefits the environment but also leads to faster, more efficient, and user-friendly APIs. It's a win-win: better performance for users, lower operational costs for providers, and a positive impact on the planet.
Also, now that you've added the cache headers there is another added benefit in traffic reduction: Browsers, and cache-enabled HTTP applications, will not even bother to make a HTTP request for a resource they already have in their local cache.

At first much of this can seem a bit scary, and worries of "how do we invalidate data" start to creep into your mind, but all of this is a solved problem and its simply a case of learning a bit more about the amazing caching mechanics of HTTP.
Start with these resources:
Then pop into the comments with questions, or ideas for what to cover in future articles.
If this has peaked your interest but you need a bit more help, Phil Sturgeon is available for consulting (avalanches dependent) and you can schedule a call to get stuck into all this and more.