
Let's Stop Building APIs Around a Network Hack


JSON-API has been one of the most popular standards for API development for a while now. It was conceived in 2013, battled through some rather different RC versions (changing drastically as it went), finally stabilizing with v1.0 back in mid-2015.
My interest in JSON-API has changed substantially over the years. Initially I avoided it like the plague, later I recommending it, and now I generally suggest folks skip it if at all possible.
Besides trying to standardize how you represent items, collections, meta data and errors (an excellent goal!), it sets out to solve a lot of problems such as Compound Documents.
The concept of a “compound document” — in the API world at least — is the art of squashing related data into the main requested resources. This is done to reduce the number of HTTP calls a client has to make.
Clients have for a long time been very unhappy making multiple HTTP/1.1 calls, especially over mobile networks. That concern has had a noticeable impact on how we design APIs. Multiple calls is considered a point of bad design, to the point where fetching a user will include the companies they work for, and that includes the locations a company might have, and that includes something else…
That was a bit of a mess, so conventions and standards were invented to make those includes optional, and JSON-API was one of the main contenders.
Somewhere in 2013 I also released a tool called Fractal, which was based off of code I’d been running in production since early 2013. The goal there (other than serialization) was the same thing, to facilitate embedding and nesting includes optionally.
In 2013 this all made sense. Multiple calls were bad, so we had to reduce those, without assuming too much and making our requests slower than they should be. This continued to be valid for a long time, even in 2015 when JSON-API was finalized.
Guess what else was released in May 2015? RFC 7540, otherwise known as HTTP/2. In retrospect this seems highly poetic, as HTTP/2 kinda makes the compound document aspect of JSON-API a little bit pointless, and compound documents to me go hand in hand with what JSON-API is as a standard.
Not to just pick on JSON-API, it also makes Fractal’s nesting/embedding feel silly, like it should be ripped out in a future version.
What’s the Difference?
There are plenty of resources out there explaining the differences between HTTP/1.1 and HTTP/2, so I’ll let them cover it.
The main point here is that HTTP/1.1 forces you to handle DNS, HTTP handshakes, SSL negotiation, etc., on every single call, and if your homepage wants 10 things from the API then it’s doing all of that junk 10 times…
HTTP/2 does all of that once, then you just make those calls back and forth. You can make those calls asynchronously, and fetch more data for those items as the responses come back. You requests all the A’s, then the callback for that async request asks for some B’s as and when the A’s respond. And C and D.
If you can use Server Push then you don’t have to wait for the A’s to respond before you can request the B’s. The server will just start sending you the B’s!
Seriously, this shit is fast.
Bla Bla Compound Documents. What else?
To me JSON-API has always mainly been about reducing the size of a payload response via network hacks like compoound documents, but there is another strategy used. Sparse Fieldsets — an idea fairly fundamental to GraphQL also — lets clients specify the fields they’re interested in, so the API can send only those fields.
GET /articles?fields[articles]=title,bodyWhilst sparse fieldsets can save a few kbs, there are plenty of other ways of trimming down the size of the response.
The entire mindset of “more handshakes = bad” has forced us to shove fields into the same resource to avoid making new resources, or sub-resources. Now that we don’t need to be scared of it, we can stop using hacks like the partials rade-off I recently proposed, and move towards having more resources that are a bit more targeted in scope.
Invoices don’t need payment status, or an array of order items, so we don’t need to worry about trimming down the response at the field level, they can just be their own related resources, discoverable with hypermedia controls.
If splitting up resources sounds like a big change and you want to just squash that actual response, HTTP/2 has your back there too. Headers are compressed with HPACK, which is similar to GZIP but a little better, and its something Cloudflare are pretty excited about.
That’s not to mention that the whole protocol is binary instead of plain-text, which gets you another nice boost. If you’re still sad about JSON being slow, you can use content-negotiation to add BSON or Protobuff to your REST API, which is a large part of whats getting people so excited about gRPC.
In general, once again, the potential speed benefit of skipping a bit of that JSON coming back using sparse fieldsets, seems to be lost in the idea of making your API be less variable, having more targeted resources, which are drastically more cacheable at the network level.
HTTP/2 Support in the Real World
NGINX already supports HTTP/2. Some programming languages like Go have built-in HTTP/2 support, so you can enjoy the full benefits of HTTP/2 like Server Push. NodeJS too.
Everyone else can at least leverage multiplexing by slapping Cloudflare, Fastly, etc., in front of their HTTP/1.1 setup.
But the Browsers…
Currently not 100% of browsers support HTTP/2 in it’s entirety, but the situation is pretty good.
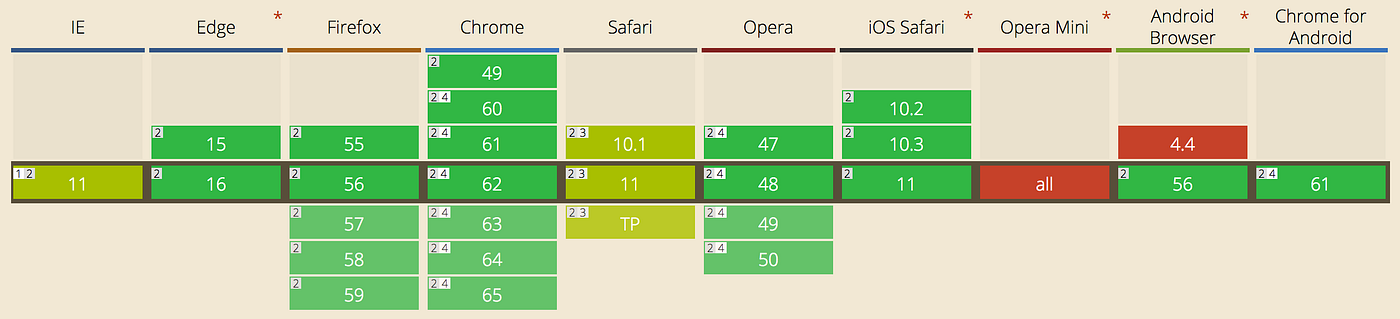
If your API is predominantly web-based, and older browser support is important, or you have no idea which browsers are going to be hitting it, then maybe you need to continue worrying about network hacks like compound documentation.
The New World of API Design
Combining HTTP/2 with targeted, network cached endpoints (via Fastly, Varnish, Squid, etc), makes Hypermedia Controls (HATEOAS) seem waaaaaaaay less silly.
I’m not waiting for a response before I see what actions I can take next, that’s slow! — Fictional Narrative Device
No longer! HTTP clients net-http2 in Ruby make asyncing up your calls nice and easy, so you can run actions in callbacks as soon as the responses come in.
Hypermedia in general seems a lot more viable when you’re not terrified of the transportation layer being slow.
It also means you’re not going to be scared of making a sub resource. At work right now we have GET /users and they want to shove "locations” in there (every WeWork location that a user has access to).
That would be how you’d want to do it in 2014, but in 2017 that should be GET /users/123/locations or GET /locations?user_uuid=123, or who cares. It just doesn’t need to be jammed up in there, slowing everyone down, just in case somebody needs it.
Includes, partials, etc., can all graduate to being actual brand new requests, instead of being some weird network hack because we were scared of handshake time.
But Adding This to REST Sounds Hard!
Folks often say “Why would I want to waste time making a REST API do this when I could just use X.”
In the same way that JSON-API feels a little silly to me now, it makes GraphQL feel substantially less useful… Anything designed around this network hack no longer feels as useful as it once was.
Well, GraphQL is the king of all glorified network hacks, and gRPC is literally just HTTP/2 + Protobuff, I’m left realizing these little niche API setups are not quite as useful as their marketing sites are making out.
If you already have a REST(ish) API, you can just start using HTTP/2 right now and get half the benefits of gRPC, and no longer care about many of the “benefits” of GraphQL.

Maybe you can remove the (ish) from your REST(ish) now that you’re not quite as scared of making more HTTP calls.
These previous solution were far from perfect, and I’m going to write about real-world issues I’ve struggled through with compound documents in the next article (done!) I don’t think anyone should rush out and change everything right now, but recognize the changing environment around the web.
As the web evolves the standards evolve to meet changing requirements, and as they evolve we no longer need as many hacks to get the job done. Frontend developers aren’t make CSS image sprites anymore, and JS/CSS combination is going away too.

HTTP/2 is a representation of what developers needed, and now we can use HTTP in its entirety, without needing so many network hacks to make it performant enough to get the job done.
Btw if you’re wondering what standard/specification I would recommend instead of JSON-API, I’m wondering the same thing. It’s between Siren and just naked-JSON + HTTP Problems RFC + JSON Schema. Picking one format to rule them all is impossible, but Siren certainly looks excellent.



