
There's No Reason to Write OpenAPI By Hand


Some API developers use API descriptions to plan the interface of an API before building it, which is known as the "API design first" workflow. Others build the API then generate (or manually produce) API descriptions later, which is the "code-first" workflow. We wrote API Design-first vs Code-first recently to help get you up to speed on the differences, but how do you actually create these API descriptions?
Many of these API descriptions (OpenAPI, JSON Schema, or GraphQL Schemas) involve writing out a bunch of special keywords in YAML, JSON, or another text language. Neither the design-first or code-first crew enjoy writing thousands of lines of that by hand. Why? Well, say you've got a list of integers:
schema:
type: array
description: List of IDs
items:
type: integer
description: Pet ID
Designing an API with 100 endpoints like that will get you through at least one keyboard (maybe two if it's a Macbook). Designing a few APIs could drive you bonkers.
Let's look at some alternatives to hand-rolling your own homegrown artisanal YAML, and how these approaches fit into design-first or code-first. More importantly, let's see how they can be used to achieve the ultimate goal for API designers: one source of truth for API descriptions that power mocks, documentation, request validation, shareable design libraries, and more.
Annotations
Some programming languages support a syntax-level feature called "Annotations", for example Java Annotations. An OpenAPI annotation framework provides a bunch of keywords that help the API developer describe the interface of the HTTP request and response, and hopefully it's telling the truth.
class UserController {
@OpenApi(
path = "/users",
method = HttpMethod.POST,
// ...
)
public static void createUser(Context ctx) {
// ...
}
}
Some languages do not have any support for annotations, and they achieve this with docblock comments.
/**
* @OA\Get(path="/2.0/users/{username}",
* operationId="getUserByName",
* @OA\Parameter(name="username",
* in="path",
* required=true,
* description=Explaining all about the username parameter
* @OA\Schema(type="string")
* ),
* @OA\Response(response="200",
* description="The User",
* @OA\JsonContent(ref="#/components/schemas/user"),
* @OA\Link(link="userRepositories", ref="#/components/links/UserRepositories")
* )
* )
*/
public function getUserByName($username, $newparam)
{
// implementation logic ...
}
In JavaScript it looks a bit like this:
/**
* @swagger
* /users:
* get:
* description: Returns users
* produces:
* - application/json
* responses:
* 200:
* description: users
* schema:
* type: array
* items:
* $ref: '#/definitions/User'
*/
app.get('/users', (req, res) => {
// implementation logic ...
});
This approach is the oldest around, and is primarily used by the code-first people. It's easy to understand why: you wrote the code already, so now lets get some docs! Sprinkle some keywords around the code, and the annotation system will integrate with your framework to emit a /docs endpoint, and boom, you've got some documentation. Great, if all you want is documentation.
Design-first people also sometimes use this approach. They design the entire API (writing YAML by hand or with one of the other approaches we're going to mention), then use Server Generators like openapi-generator or swagger-generator to create their API code. This API code is created from the machine-readable documents that were made in the design process, and the code that is generated is chock full of annotations already, which in turn can generate documentation. Throw those machine-readable documents away, the annotated code is the source of truth now... right?
One downside to annotations is that they don't confirm the code is doing what it says. I've heard the argument "Annotations are closer to the code they describe, so developers are more likely to keep it up to date". Do not confuse proximity with accuracy. Developers can forget to make the changes, and developers can make mistakes.
Annotation users need to find a way to contract test the actual output against these annotations, which we've written about before in Keeping Documentation Honest.
The tools in this article generally involve the machine-readable OpenAPI / JSON Schema files around, so you need to export them back to a machine-readable format in order to compare them to the code... This means running a command in the command line which pulls the annotations out into a machine-readable file, then running a tool like Dredd or a JSON Schema validators, which is a pretty awkward step.
Design-first is incompatible with all this, unless you chose to design the API, then generate code with annotations, then figure out how to keep the code, the annotations AND the machine readable designs up to date. If there's anything worse than two sources of truth it's three...
For this reason, folks who like design-first run and hide from annotations, but the folks who like annotations generally really really love them because to them their code is the source of truth and if they can crowbar one of these test suites in to confirm that then they're perfectly happy. This mindset can lead to API clients being a bit of an afterthought, but that's another topic for another article.
DSL (Domain Specific Language)
A few DSLs popped up over the years, created by people who wanted to create API Descriptions, but didn't fancy writing it out in that specific format, with articles like Making OpenAPI / Swagger Bearable With Your Own DSL.
DSL's can be used in code-first or design-first. You have your code, you have your DSL-based descriptions, and whatever format they were written in doesn't make much difference here.
;;; ENTITIES
(define pet-entity
(entity "Pet"
'race (string "What kind of dog / cat this is (labrador, golden retriever, siamese, etc...)" "Labrador")
'origin (string "Country of origin" "Egypt")
'birthday (datetime "Birth date of the pet" "2017-10-20T00:14:02+0000")
'species (string "What kind of animal is this" "dog" #:enum '("dog" "cat"))))
(define $pet (schema-reference 'Pet pet-entity))
;;; RESPONSES
(define list-pets-response (jsonapi-paginated-response "List of pets" ($pet)))
;;; REQUESTS
(define pet-request (json-request "Pet Request Body" ($pet)))
;;; MAIN DOC
(define swagger
(my-service-api-doc "Pet Store" "Per store pets management"
(path "/pets") (endpoint-group
'tags pet-tags
'parameters (list store-id-param)
'get (endpoint
'operationId "listPets"
'summary "Retrieve all the pets for this store"
'parameters pagination-params
'responses (with-standard-get-responses 200 list-pets-response))
'post (endpoint
'operationId "createPet"
'summary "Create a new Pet record"
'requestBody pet-request
'parameters (list xsrf-token)
'responses (with-standard-post-responses 200 single-pet-response)))
This is shorter than the OpenAPI YAML it replaces, but it's also another format for people to learn. People who know how to write up OpenAPI will need to learn this format, and the folks familiar with a different DSL will have to learn this format too. Your editor will also need to learn about this format if you want autocomplete, syntax highlighting, linting and validation. The "native" description formats all have this, but these DSLs usually do not.
This approach, just like annotations, do not help you ensure that what you're writing in the DSL is actually correct. The contract written down in the description could be completely incorrect. Some DSLs like Rswag aim to solve this by having their DSL be written as integration texts. The source of truth for how you create OpenAPI is literally integration tests:
describe 'Blogs API' do
path '/blogs/{id}' do
get 'Retrieves a blog' do
tags 'Blogs'
produces 'application/json', 'application/xml'
parameter name: :id, :in => :path, :type => :string
response '200', 'blog found' do
schema type: :object,
properties: {
id: { type: :integer },
title: { type: :string },
content: { type: :string }
},
required: [ 'id', 'title', 'content' ]
let(:id) { Blog.create(title: 'foo', content: 'bar').id }
run_test!
end
end
end
end
This approach is pretty handy for Test-driven development (TDD) advocates, but you're just writing OpenAPI in another form which isn't particularly any shorter, just more Ruby-ish. RSwag was a big favourite at my last job, but it's had a rough time getting updated onto OpenAPI v3.0 (still a work in progress 3 years after OpenAPI v3.0 was released).
Writing in a DSL or annotations means you're at the mercy of that maintainer to support functionality that you could already use if you could just... edit the OpenAPI yourself.
Graphical Design Editors
What is the alternative to editing the files but now having to wrangle YAML? Visual thinkers and non-technical people might want a wizard mode, the ability to create arrays of objects with a few buttons, and selection boxes for shared models without having to think about the filepath. Graphical design editors are pretty new in the world of OpenAPI and GraphQL, with a few popping up over the last year or two.
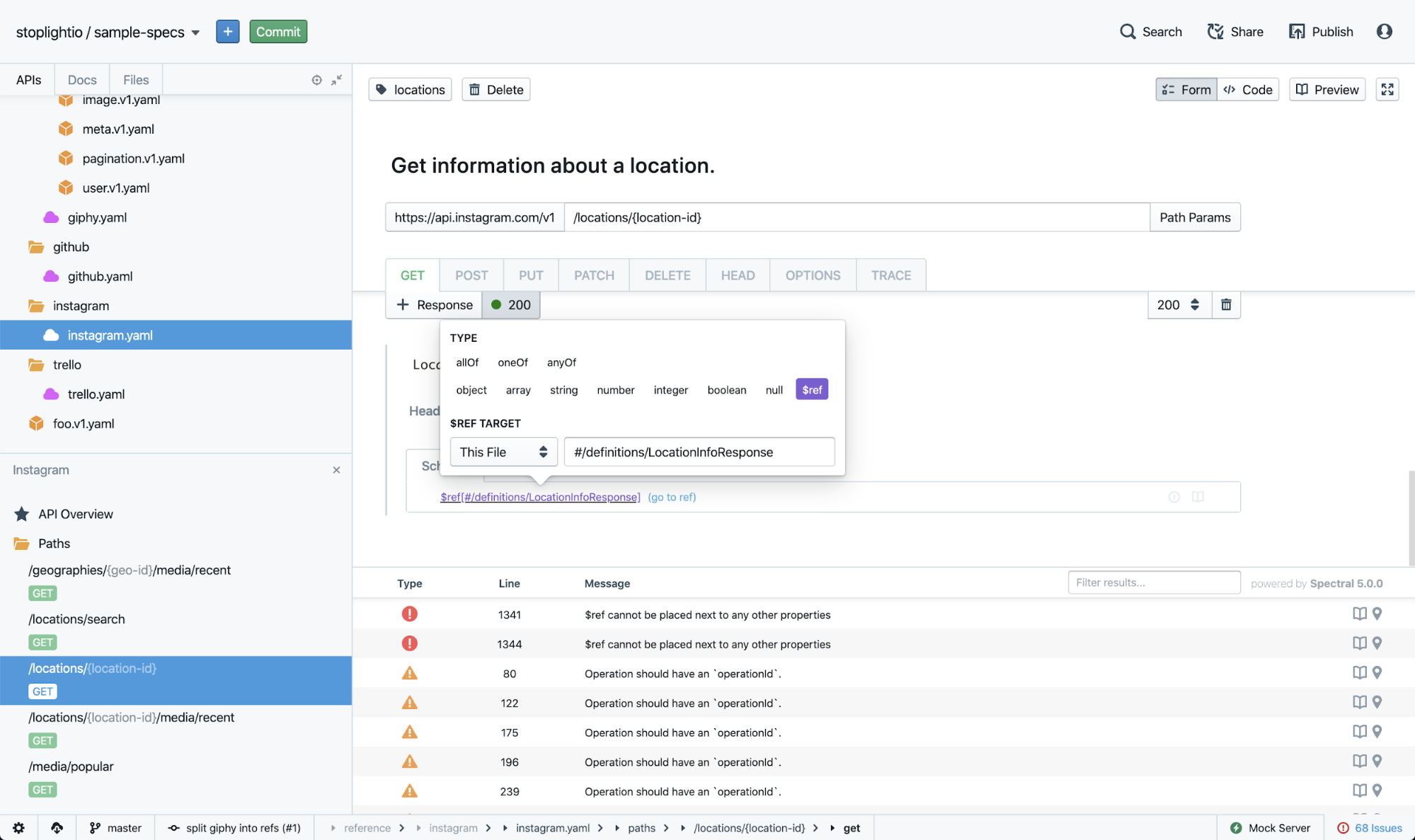
Two years ago I was looking around for a beautiful, effective graphical editor to satisfy some code-first sticklers pushing back against API design-first at WeWork. I figured a GUI would help them convert, and Stoplight told me they were planning a new GUI. Shortly after seeing their amazing prototype I joined the company to help roll it out to even more folks, and now my job is gathering feedback from the API community to make Studio, our open-source tools, and the upcoming SaaS platform even better. 🥳
Modern GUI editors have mocks and docs publishing built right in so you no longer have to figure out your own "DocOps". Editors like Stoplight Studio add "Design Libraries", where you can manage shared models between multiple APIs in an organization. These editors support organization-wide style guides to have the editor lint during editing (and/or in continuous integration) to enforce consistency, and a bajillion other things.
There are a bunch of different OpenAPI-based graphical editors around, check out our list on OpenAPI.Tools:
GraphQL fans, who are having a lot of the same conversations right now, can check out these:
Some editors will help you with part of the API design life-cycle, but make a lot of difficult assumptions about what order you're going to do what in. They might help you create a design, then they'd assume you wanted to export it and generate some code, leaving your machine-readable description documents floating around to become obsolete, and giving you no way to edit them even if you wanted to. Other tools let you import an OpenAPI document, but convert it to their own internal format and provide no way to pull the OpenAPI back out again.
Using tools where the format changes entirely at different points locks you into whatever workflows they support, instead of letting you plug-and-play your own tooling at every stage of the process. For me the ideal solution is supporting a git-based flow, where they live in the repository (maybe before the code exists), and regardless of how these API descriptions were created you can edit them and send a pull request back to that repo with the changes you made.
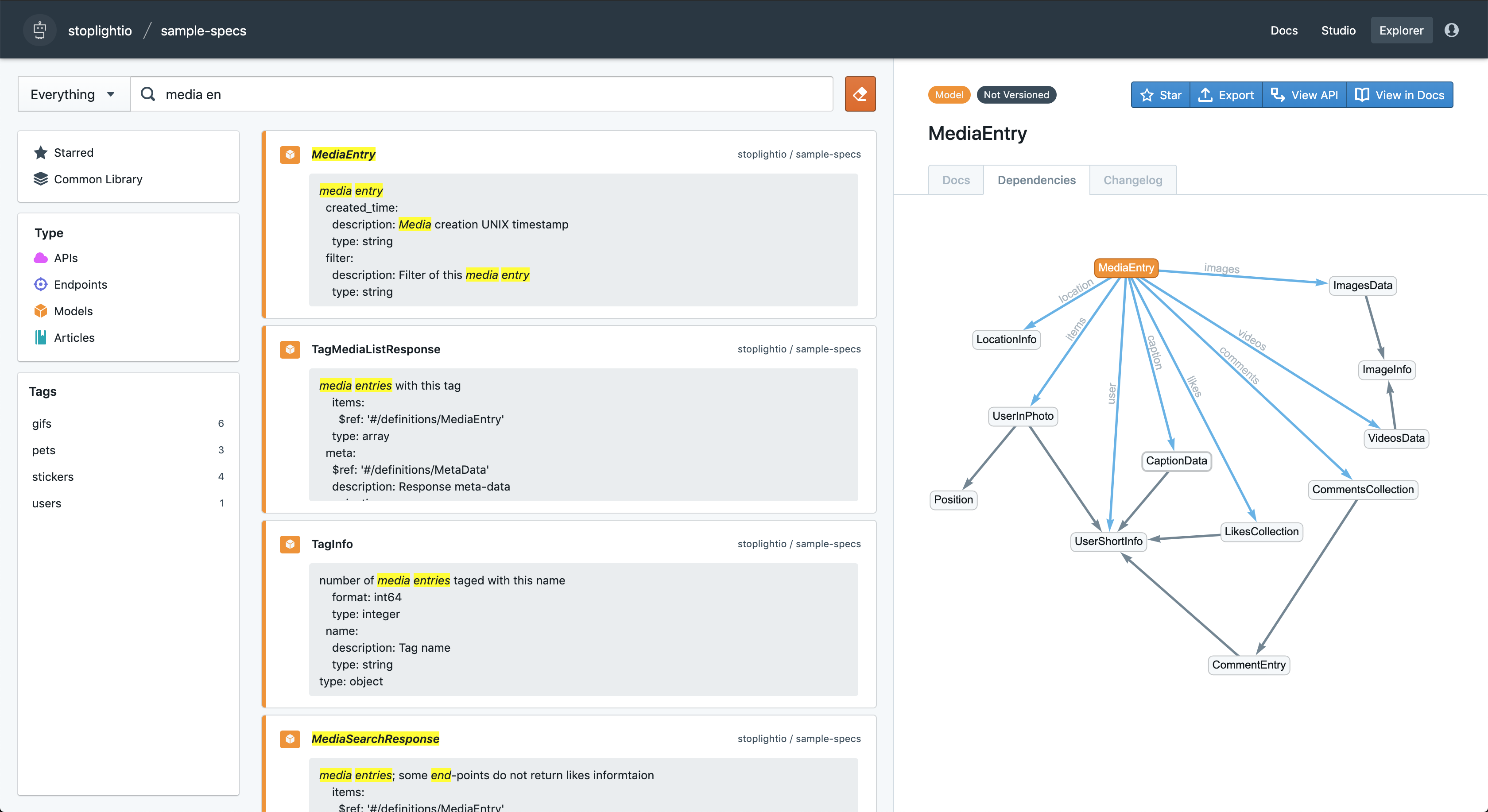
Leaving the machine-readable source of truth in the repo means any integrations are possible. Continuous integration processes can deploy documentation to any documentation provider, you can use use any code-generators to build and publish SDKs, sync with popular HTTP clients like Postman or Insomnia instead of maintaining API descriptions and bookmarks, and fully take care of contract testing in-repo or end-to-end repositories. If your editor is backed by a design library then the repositories will be analyzed on push, allowing others to use these updated models instead of having 1000 different versions of a "User", "Company" or a "Flight".
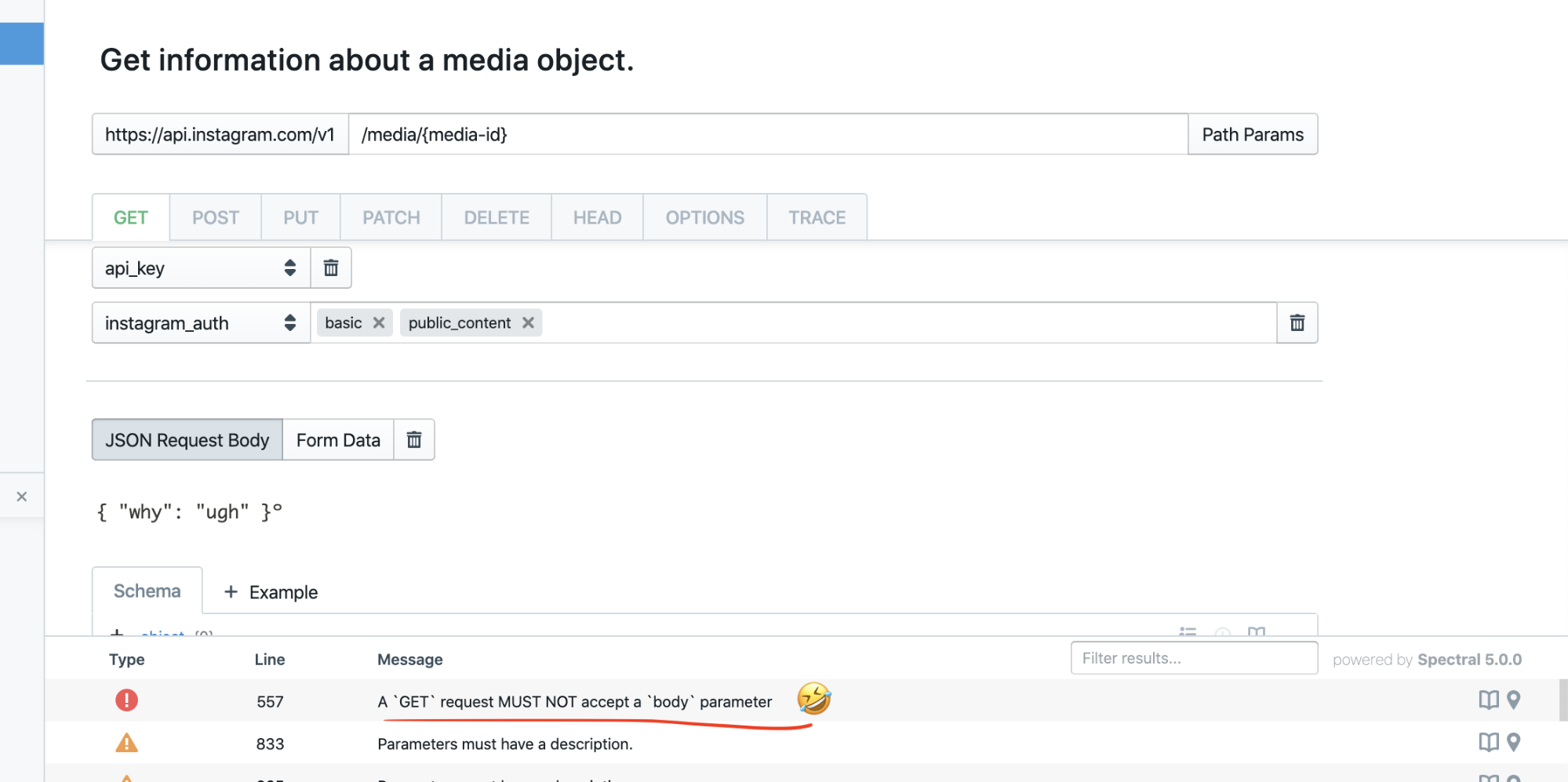
But, how does having an editor help you catch mistakes? Stoplight Studio has a built in HTTP Client, which amongst other things is watching for mismatches between the OpenAPI defined for the API and the actual HTTP requests you send. It will also notice mismatches between OpenAPI and the responses coming back, so you'll see mistakes popping up like this:
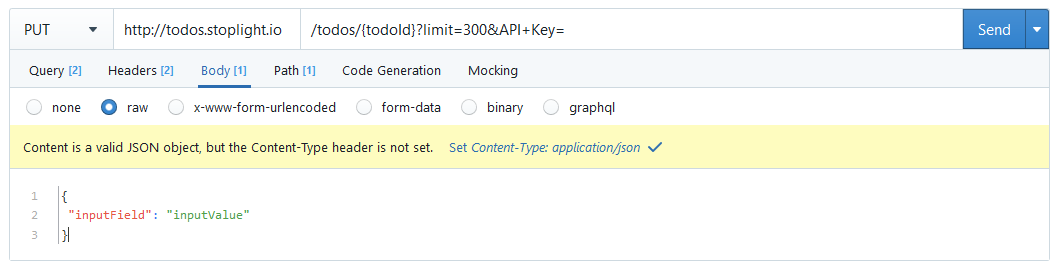
Noticing contract mismatches in a HTTP client is all well and good for spotting mistakes in requests you're making, but you'll want to automate this checking too.
Instead of having all your model validation rules and header checking written in code, and then also writing it down in the API descriptions, use the existing machine-readable descriptions for validating incoming requests. If your request logic is powered by API descriptions, there is no need to check that it matches the code, because it... is the code. Framework middlewares for every framework and every language implement this. NodeJS has about 100.
- PHP: league/openapi-psr7-validator
- Node.js: fastify / express-swagger-ajv-validator / express-openapi-validate
- Ruby/Rails: committee
- Python: connexion
- Perl: Mojolicious::Plugin::OpenAPI
The Rails one, for example, takes a single line to set up the Rack middleware:
use Committee::Middleware::RequestValidation,
schema_path: "./openapi.yaml"
That covers incoming requests, but how to ensure the responses are doing the right thing? Some of those middlewares will implement response validation too, which can confirm the response coming through it matches the code. This is a great thing to enable in dev and staging, but turn that off for production. 🤣
Another approach to checking responses is contract testing. Instead of having some DSL-based integration testing suite specifically for checking the responses, or using some other tool where you have to write out the contract again, you can can just use the API descriptions as contract tests. So easy, and all it takes is a few lines of code to mush the response into a data validator for the API description format of your choice.
Another approach is using Prism Proxy in end-to-end testing to blow up if any requests or responses are invalid throughout the test suite. This can be implemented with little to no buy in from the folks producing the APIs, because you can just funnel existing cross-API traffic through the proxy in the testing environment without modifying any code.
Code first and editors do not jive at all, because the editors do not understand the annotation system in the Java/PHP/Python/etc source code. According to an extremely scientific poll on my Twitter, 35% of teams are battling through with a mixture of code-first and design-first.
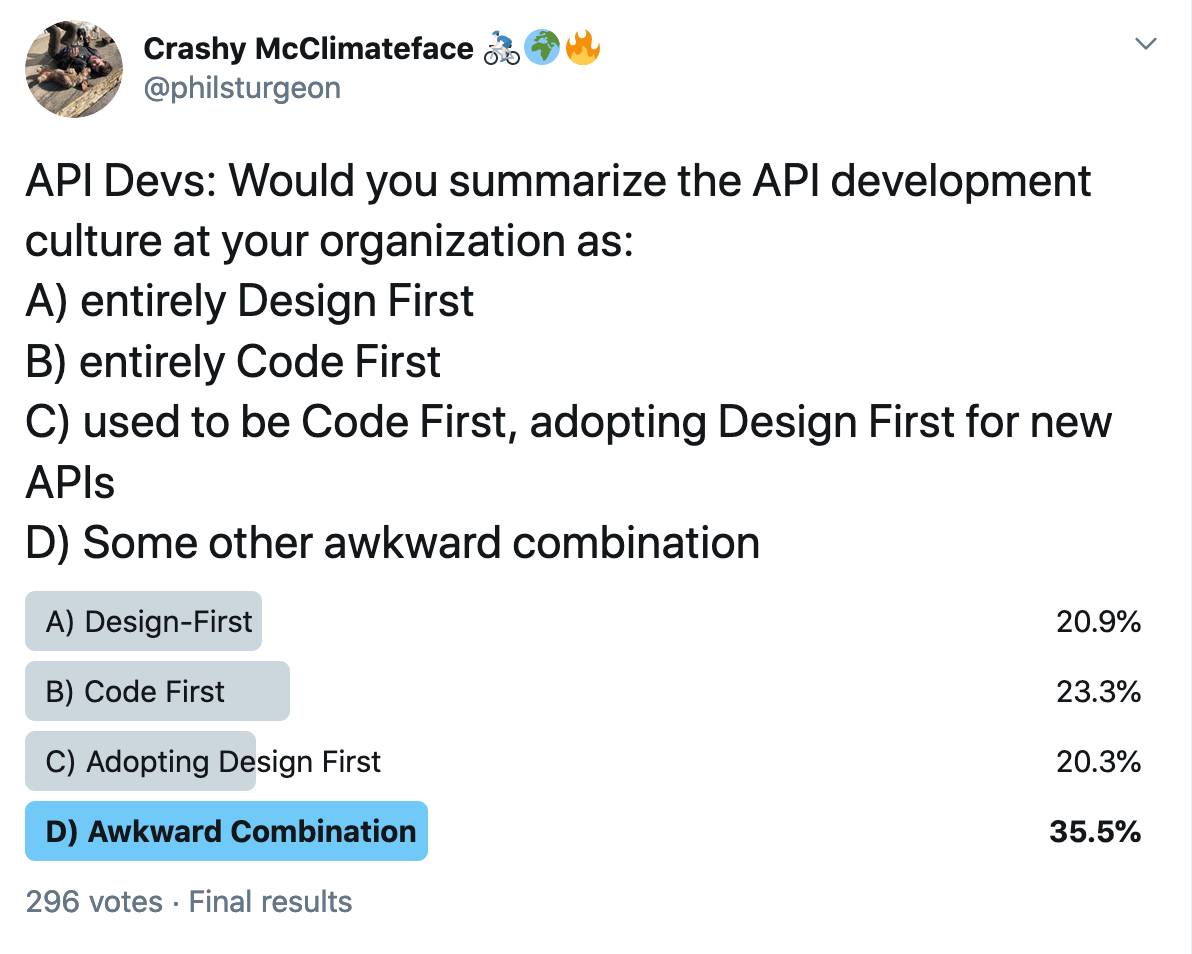
So long as the code-first folks add a build step (pre-commit or in CI) to generate a machine-readable file in the filesystem (like openapi.yaml), then hosted solutions like Stoplight Platform can analyze repo contents to give the same hosted docs, mocks, and design libraries, to all the projects. No editing for them of course, but those who want editors are on the same remaining workflow as those who don't. 🥳
Annotations-as-Code Web Frameworks
Many web-frameworks third-party support for request/response validation, which we've mentioned above. This is usually in the form of middlewares or just baked right in, and they read API descriptions from the filesystem.
Other frameworks have first-party or third-party support for annotations, which are purely descriptive repetitions of the actual code they sit above at best. At worst they're just lies.
There is a new category of API description integration popping up in some web frameworks which is somewhat like Annotations or DSLs, but instead of being purely descriptive it's actually powering logic and reducing code, giving you one source of truth. Effectively they do the same thing as the machine-readable powered validation middlewares, but instead of coming from openapi.yaml the logic is coming from the annotations.
Here's an example from tsoa, which is a TypeScript and NodeJS framework for building OpenAPI-compliant REST APIs.
import { Body, Controller, Get, Header, Path, Post, Query, Route, SuccessResponse } from 'tsoa';
import { User, UserCreationRequest } from '../models/user';
import { UserService } from '../services/userService';
@Route('Users')
export class UsersController extends Controller {
@Get('{id}')
public async getUser(id: number, @Query() name: string): Promise<User> {
return await new UserService().get(id);
}
@SuccessResponse('201', 'Created') // Custom success response
@Post()
public async createUser(@Body() requestBody: UserCreationRequest): Promise<void> {
new UserService().create(request);
this.setStatus(201); // set return status 201
return Promise.resolve();
}
}
This is a brand new approach. Instead of descriptive annotations or comments shoved in as an afterthought, the API framework has been designed around the use of annotations.
Beyond simple things like request validation, TSOA handles authentication quite nicely. Numerous times I've seen API documentation say bearer tokens are required, or an OAuth token needs a certain scope, only to find out the developer forgot to register that in the API controller. Free sensitive data anyone?
TSOA solves that by having you register security definitions, then reference them in your annotations, and have middlewares created to handle the actual logic. This way the annotations are all the actual source of truth for authentication, instead of just being lies in comments or YAML.
Then, OpenAPI can be generated from a command:
tsoa spec
Whilst I definitely have a preference for design-first development for all the prototyping benefits it brings (changing a few lines of YAML in an awesome GUI is easier than rewriting a bunch of code every time you get feedback on a prototype), this new approach for making annotations useful is very much closing the gap. If you're going to use a code-first approach, you should absolutely try and find a framework like TSOA to power your API and reduce the chance of mismatches.
Ideally the file-based middlewares and these new annotation-driven middlewares would share a bunch of dependencies. As I mentioned before there's a million of these file-based validation middlewares out there, and some get more love and attention than others. I convinced three PHP request validation middleware authors to combine efforts and make one amazing one, so it'd be great if some of these other middleware developers could team up with some annotations-as-code framework people to allow them as inputs to their existing middleware. With OpenAPI v3.1.0 coming out soon, it'll be a lot better for us tooling vendors to start collaborating on a smaller number of higher quality tools, instead of everyone battling through the upgrade process individually.
Whatever you're up to: code-first, or design-first, make sure you're doing what you can to avoid maintaining two sources of truth. Of all the options possible, try and stick to:
a) awesome editors like Stoplight Studio or GraphQL Designer to maintain API description documents, then reference them in the code, or
b) frameworks which support annotations-as-code that knows how to express itself as API descriptions
Just don't maintain code and descriptions separately, because having two sources of truth just means waste time trying to find out which one of them is lying.



