
Does REST and Hypermedia Have a Place in the Modern API Landscape?


Nobody out there thinks you should always use REST for every single API being built, nor should you ever use any one paradigm for everything, but a growing number of people misunderstand REST so badly they think they never need it.
As with most things, there is a whole bunch of nuance that the average developer doesn’t have time to consider when they’re trying to get their job done, but some of that busyness can come from solving problems that popped up because the wrong paradigm was being used in the first place.
REST can be considered a bunch of layers of abstraction that help you talk to the client developers less, whilst enabling them to build more sturdy and consistent applications.
This is achieved in a few ways, mostly by leaning on the existing semantics of whatever protocol the REST API exists in, and usually that is HTTP. Building a REST API in HTTP usually means deferring to existing HTTP semantics to achieve the concepts REST sets out to achieve instead of inventing your own conventions. Instead of having to know how Rachel built caching in their API, I should be able to just enable a generic caching middleware and have that work.
Instead of writing a bunch of code to know every single application error an API might respond with and try to figure out if it’s one I can retry or not, clients can consult the Retry-After header.
Folks often complain that REST is hard because they have to learn about HTTP methods and their meaning, and different status codes. Whilst learning HTTP might take some time, the conventions of HTTP are shared with a huge ecosystem of tooling, which you are supporting without even knowing about it by using these conventions.
People have always tried to avoid having to learn this stuff, and a lot of the time RPC ends up being what people go with. For a lot of developers, having a collection of functions that operate over the Internet, fetching some data from a thing and triggering a thing is the pinnacle of an API. In doing that they are creating a lot of their own conventions and losing a lot of the benefits that REST sets out to provide.
Going back to the comment “REST is a bunch of layers of abstraction on top of RPC”, let’s look at a diagram I’m sure most of you are familiar with: the Richardson Maturity Model.
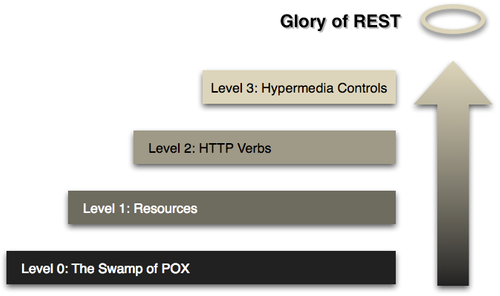
This is a visualization created by Martin Fowler in his article introducing the Richardson Maturity Model. The model takes the name of Leonard Richardson, and his talk about API maturity.
There are a few common concerns with this diagram, mainly with “Glory of REST” at the top, and the “Swamp” at the bottom. For the same reason I have concerns about the word “maturity” being used. This has the unfortunate effect of making it seem like REST APIs are amazeballs and everything else is stupid. That’s not what anyone was trying to say, but it’s the conclusion a lot of people draw.
When talking about this diagram I usually explain that an RPC API doing a job that a REST API would be better suited at is gonna suck. I wouldn’t take my mountain bike on a 200mi ride and I wouldn’t take my carbon road racer on a downhill mountain bike course. A good thing used for the wrong task very quickly starts to look like a bad choice, without the thing being inherently bad.
Without wanting to talk about glory: an API getting the full benefits of REST is going to be better protected against a lot of the awful bullshit I spend so much time trying to help companies avoid or solve, but again those benefits are all hardy awesome mountain biking components that will slow me down in a road race.
Another concern is that Martin talks about Plain Old XML, and these days some folks talk about POJOs (Plain old JSON Objects).
API specifications (metadata to describe your data model) are available to all API developers regardless of their paradigm or implementation of choice, so that should be taken out of consideration. REST folks use JSON Schema, gRPC people use Protobuf, and GraphQL users have GraphQL Types. Some folks might be working with POX/POJO if the decision makers in charge of the API development team are committed to ignoring modern best practices, but it is nothing to do with paradigm.
Updated Richardson Maturity Model
So with the holier-than-thou concern out the way, let’s take a look at my attempt to update the Richardson Maturity Model. I’m keeping the name because I am not changing anything conceptually from the original talk.
Each layer briefly mentions some of the functionality it enabled.

0: RPC
What we really have as an issue is that RPC in its most basic form usually ignores a lot of HTTP concepts. Instead of leveraging the uniform interface of HTTP and its full semantics, and instead of using HTTP as a transfer protocol, it uses only the transportation aspect. A transfer protocol helps you know when or if you need to make a request, instead of just ferrying data up and down the wire.
Most RPC implementations interact with a single endpoint, and most interaction is using a single HTTP method. Very few generic HTTP conventions will work for something that is just the most basic RPC.
If the RPC is following a specific standard then tools built for that standard will work, but generic HTTP conventions do not apply.
1: Resources
Two common confusions here, firstly this is not about having /bikes and/bikes/abc123 in that standard collections and plurals and resources CRUD pattern we are often used to. I have fallen for this in the past.
Resources are technically the same thing as endpoints, but there is an intentional distinction. Endpoints are often thought of more like functions, and the intention is that you call a function whenever you want to do a thing, but that is again most transport that transfer, and is usually a sign of RPC thinking: call a thing and do a thing.
Resources are more like identifiers, a unique thing which lives in a specific place, and can be identified by that thing. It is the ultimate unique identifier in HTTP world, because whilst two companies could have different products with the same alpha/numeric ID, and even UUID collisions are mathematically possible, we are never going to run into collisions with https://cannondale.com/bikes/abc and https://surly.com/bikes/abc.
The URI (Uniform Resource Identifier) is not wildly exciting in itself, but having unique URIs for everything means you can start adding specific headers to different resources, which can be stored along with the responses as metadata.
This lets resources declare their own cacheability, which is one of the big things REST talks about.
Cache constraints require that the data within a response to a request be implicitly or explicitly labeled as cacheable or non-cacheable. If a response is cacheable, then a client cache is given the right to reuse that response data for later, equivalent requests.
The advantage of adding cache constraints is that they have the potential to partially or completely eliminate some interactions, improving efficiency, scalability, and user-perceived performance by reducing the average latency of a series of interactions. The trade-off, however, is that a cache can decrease reliability if stale data within the cache differs significantly from the data that would have been obtained had the request been sent directly to the server.
— Fielding, Roy Thomas. Architectural Styles and the Design of Network-based Software Architectures
RFC 7234 handles this nicely.
The goal of caching in HTTP/1.1 is to significantly improve performance by reusing a prior response message to satisfy a current request. A stored response is considered “fresh”, as defined in Section 4.2, if the response can be reused without “validation” (checking with the origin server to see if the cached response remains valid for this request). A fresh response can therefore reduce both latency and network overhead each time it is reused. When a cached response is not fresh, it might still be reusable if it can be freshened by validation or if the origin is unavailable.
— IETF: RFC 7234
Having unique URIs for things also means HTTP/2 Server Push can work as expected.
This is a huge benefit of leveraging HTTP properly, using it as a transfer layer and not a dumb tunnel.
2: HTTP Methods
Methods add a lot of important semantics to the type of thing happening in the request. IF caching is used, the caching component will know it can cache a GET request, but if a POST or DELETE is made to that same resource, it knows it should get out of the way.
Client-side logic like automatic retries are now possible. A retry can help when an API is taking a long time to respond, a client application might bail on the request and try again. With a GET there are barely any downsides here, because it is an idempotent request that should not have any destructive actions. You could GET a thing 3479 times and you would just have that data.
Retrying a POST could be dangerous, as maybe before the timeout was reached, it had managed to change some records in the database, send some emails, charge a credit card, etc.
PUT and PATCH would be fine, because PUT is idempotent and just obliterates the result, and PATCH usually has a “from” and “to” meaning if the request is made a second time the “from” would probably not match.
People see POST vs PUT vs PATCH and get upset about having to learn the difference, but again these semantics are baked into HTTP tooling instead of everyone being forced to updatePartialThing and updateFullThing and invent other conventions around idempotency...
If you are a fan of gRPC you will be thinking that a lot of this stuff sounds possible, and you’re right! The gRPC “HTTP Bridge” adds these two layers of abstraction, to make it a bit more HTTPish. It’s not a REST bridge as some people call it, because it’s missing this next layer…
3: Hypermedia Controls
Hypermedia Controls is shorthand for “Hypermedia as the Engine of Application State” (HATEOAS), which is quite a simple concept. Instead of an API being just a datastore-over-HTTP, it becomes a state machine-over-HTTP. It’s still got data, but it can also offer “next available actions” in self describing ways.
Think about an invoice saying it is payable, instead of you needing to figure out if it can be paid based on the lack of a paid_date, or maybe there is a status: pending, but maybe a new status gets added and pending doesn't mean you can pay it anymore... Client applications break, or need to be versioned, both of which wastes developer time and company money.
Having a link show up called “pay” if the invoice is payable means the client application knows when to pay, and so long as a good hypermedia format is used the client application will know how to pay, as the controls can mention what data is required, offering the means to validate that data client side before you even send a HTTP request to the server… transfer > transportation, helped us out again!
The most basic level of hypermedia is shoving links into the response body (thanks Resources!) but then the client has to do a lot of detective work to figure out what they can do next. In the past folks would just shrug and say “you have a URL and a link relation, that’s a good start”, but these days there are quite a few popular Hypermedia Formats around which make things a whole lot easier than that.
We’ve talked in a lot more depth about representing state in APIs for more of a general overview.
Most APIs that call themselves REST stop short of the last layer, which mean they are what many people all RESTish, or just a HTTP API. That’s not to be snotty, it’s because Hypermedia Controls make it a REST API, it is a huge chunk of the point.
Sometimes it’s a lack of education on the topic, where people just literally have no idea what HATEOAS is about. Fair enough! Other times folks think they understand it, and think that HATEOAS is about forcing you to make loads of HTTP requests to get the same amount of data. That usually shows they’re thinking about transportation and not transfer, and these days with HTTP/2 even if you were needing to make “more calls” the performance impact is negligible.
Next
Once you get to the REST part of the diagram that doesn’t mean your API is suddenly infallible and perfect in all ways forever.
Shoddy resource design will make any API a pain to work with regardless of the paradigm being used, and GraphQL developers are starting to notice that now.
A focus on model design that meets the needs of your clients is important, and APIs can evolve over time to trim away useless data, and create composite resources to minimize network chattiness. JSON Schema just got a deprecated keyword too which can make API evolution a whole lot easier.
Hypermedia + gRPC / GraphQL
When talking about Hypermedia Controls, people have said things like “That’s not just something REST can do, gRPC could do that if you used the HTTP Bridge and added links!”
Comically they were saying this in a shouty, red faced, gRPC-defending way, and my answer was “Yes! Absolutely, if you add Hypermedia Controls to a RPC API along with all these other things then you have literally made it a REST API!” REST is a collection of ideas, and you can use those ideas anywhere you like.
A few prominent GraphQL people have been trying to figure a way to get Hypermedia Controls into GraphQL for a while. If they figure it out, GraphQL would not be following this diagram exactly, but we can call “query” and “mutation” close enough to HTTP Methods to give them a pass, and the only thing missing is resources (URIs). Missing URIs is a larger problem for GraphQL because it pretty much destroys their chance of using HTTP/2 Server Push, meaning they’re left turning to vendor specific solutions like Apollo Subscriptions and other non-standard @defer extensions things for that.
Summary
Anyway, APIs don’t always need Hypermedia Controls, nor do they need any of this.
For example, full-stack developers often think REST is a waste of time because they are just trying to query the database and get that information to the presentation layer. They do not need to bake cache controls into the message itself because they can just set the caching in the client application which is probably open in another window on their machine. They know when to use retries or not, because they wrote their application codes and know what they mean, so who cares about leaning on HTTP semantics for that.
Those developers have absolutely nothing in common with developers trying to provide consistent functionality to a wide variety of client teams who might be on different floors or different continents, where communicating change or how to infer state might be a costly problem. Those teams might be using all sorts of network and client tooling like caching middlewares, monitoring services, inspection proxies, and you don’t want to restrict what tools they’re able to work with because that could lose you business.
Then there are all the scenarios in between.
Not all cars need to be bullet proof, not all conversations need a translator, not all underwear needs to be edible, and not all APIs need to be REST. 👍
Check out our article Picking the Right API Paradigm to see when you might want to consider using REST, and when you should use something else.



