
Ruby Users: Be Wary of Net::HTTP


A few months ago we released We::Call, a Ruby gem that wraps popular HTTP-client Faraday. We::Call aims to configure Faraday with as many best practices for HTTP communications by default as it reasonably can.
It’s come a long way over the last few development versions, most of which revolves around removing the deprecation logic, putting that functionality in a more "Rails-like” gem rails-sunset, and removing Rails as a dependency altogether.
Something else we’ve done, is force the use of timeouts. If you don’t define a timeout upon creating the connection, We::Call will raise an exception. This had the knock-on effect of demanding the entire dev team to consider timeouts, which has in turn improved performance throughout our architecture. Timeouts are another article entirely, but fail fast, fail often.
This leads us to the matter at hand: we noticed that timeouts were taking twice as long as they should. If we set We::Call::Connection.new(…, timeout: 5) then it would take 10 seconds. This was having awful affects downstream as you can imagine, and the thread being blocked for that long was causing awful backups in the request queues!
Somebody suggested maybe We::Call was failing to pass the timeout to Faraday correctly, and 10s was the server just timing out… This seemed reasonable, so I immediately started debugging.
After some debugging, I noticed a timeout of 1 would take 2s, 2s would take 4s, 4s would take 8s…
WHAT?!
Exasperated, I think I dumped some ridiculous search query into Google like:
why are Faraday timeouts doubled
Amazingly, I found an answer.
timeout is always doubled · Issue #612 · lostisland/faraday
_I guess this happens because it sets open and read timeout to the same value ... but it's kind of irritating :
Not a fault of We::Call or Faraday at all, but the default adapter it uses as the guts for its operations: Net::HTTP. This is clearly used by Faraday as the default because it comes baked into Ruby.
Back in 2012 a commit was made that ended up in v2.0.0, to automatically retry any request made that was idempotent:
IDEMPOTENT_METHODS_ = %w/GET HEAD PUT DELETE OPTIONS TRACE/
This is theoretically a great idea, but it ends up creating a huge mystery for anyone who is not expecting it. Some of the most experienced developers at this company had no idea it was happening, so how can we expect anyone else to know?!
It’s not like we’re just an unfortunate collection of daft people. This advice is everywhere, like in Common Patterns > Retry on Failure, a gist that appears rather high on certain search terms:
response = Net::HTTP.get_response("google.com", "/") rescue retry
This works, but it’s going to be making two attempts before that rescue retry is even hit. 😅
NewRelic does not report this as 2x requests either, just shows one NetHTTP call that measures twice as long. Maybe the NewRelic reporting could be improved, or maybe its opaque to their Ruby agent, but having this act as an uncontrollable default is terrifying.
The pull request to make it configurable has been merged and will be landing in Ruby v2.5.0 when it’s released. It keeps the default behavior unchanged, which will continue to confuse people, but at least it will allow Faraday to implement control over it in their adapter. They’ll probably default to 0 retries then using their faraday.request :retry, max: 1 you could increase that optionally.
Waiting for every application to get to Ruby v2.5.0 didn’t seem like a solution to this problem, so I started looking into alternative adapters that Faraday can use (so we can continue using all of our awesome middlewares), and typheous popped up as a strong contender.
Typhoeus Is Fantastic
Typhoeus is a popular choice for those wanting to make async calls, but are not able to upgrade their architecture to HTTP/2 yet for various reasons. I’m still pushing for more HTTP/2 to help improve and simplify our API designs, but in the meantime letting folks use typheous async stuff seems like a great move.
Not only does typheous’ async functionality mean multiple things can be done faster (making a lot of calls async is a lot faster than making a lot of calls in serial), but making bog-standard calls with typheous is a lot faster too.
Typhoeus wraps ethon, which is a low-level wrapper around libcurl. Having libcurl as a base gets us HTTP/1.1 KeepAlive support, which drastically improves the time it takes for a HTTP connection to be created.
Benchmarking this was pretty simple. Let’s create 100 realistic POST requests to ensure no caching is happening, and don’t use any features like built-in JSON serialization or async functionality.
user system total real net\_http: 0.910000 0.190000 1.100000 ( 9.382847) net\_http\_persistent: 0.980000 0.170000 1.150000 ( 9.245193) patron: 0.150000 0.110000 0.260000 ( 2.233322) httpclient: 0.150000 0.100000 0.250000 ( 2.142556) typhoeus: 0.120000 0.070000 0.190000 ( 2.138841)
Patron, httpclient and typhoeus all wrap libcurl, and they switched being fastest by .1 a few times. In the end it was a clear and easy choice to go with typhoeus due to the similarly amazing performance boost, plus the async stuff.
We trialed Typhoeus on a system that gets plenty of hits, and operates as a evaluator for remote data sources. It was the perfect system to trial it on, as making HTTP requests is pretty much all it does, and whatever can be done to speed that up speeds the whole system up.
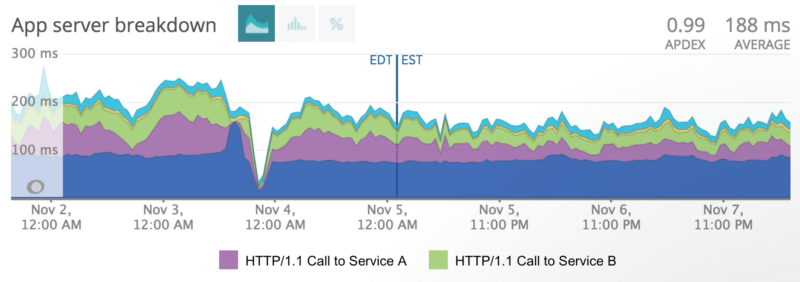
Slight improvement in times for connections to some otherwise rather slow services, after the Nov 4ish deployment.
We deployed a We::Call v0.7.0-pre1 and lost instrumentation for the rest of the day, leading to that exaggerated dip in the graph. Typheous does support NewRelic, so we deployed a fix, and you can easily see the improvement.
Typhoeus Is Not Perfect
Things cant always be 100% unicorns. Typheous right now does not seem to distinguish between "open timeout” and "read timeout”, which for our needs (and for debugging in general) is very important.
This sucks, but it sucks a whole lot less than having everything mysteriously double up without anyone knowing why.
The Typheous adapter in Faraday ≤ v0.13 is also horrendously out of date, and Typheous bundles their own now. This has been removed in master (and will be gone in v0.14). The Faraday test suite runs against the external typheous adapter, thanks to some help from the Faraday maintainer "iMacTia”.
All in all the situation is better now than it was, but there are more PRs to send, and more open-sourcing to do!
Summary
Whatever you do, make sure you’re conscious about Net::HTTP doing this thing, and if it scares you switch to one of those libcurl based adapters!
Also keep this speed difference in mind when considering switching from "traditional” REST or RESTish/RPC HTTP calls. Using a HTTP client that does not handle keep-alive will be much slower than switching to some fancy new tool that does, but that’s a false improvement.
Try to avoid throwing the baby out with the bathwater, and just use a HTTP client that turns keep-alive on for you. Or find one that allows you to turn it on yourself. 👍🏼



