
Automated Style Guides for REST, GraphQL and gRPC


Ask 100 developers where a semicolon should go, and you'll either get 100
answers, or a all-on-all fist fight. To save this from happening at work, most folks implement a style guide, which beyond helping with consistent style to avoid new developers getting shouted at for "doing it wrong". Linters can advise best practices, shout about things which are technically allowed but likely to cause trouble, and shape the API of code as it's being written (snake_case that method!) This is always done for code, and is becoming increasingly popular for API descriptions.
JavaScript users have eslint, PHP users have PHP Code Sniffer, and Ruby has
rubocop. These linters don't just check that the
user is writing valid syntax. They check against existing sets of rules,
sometimes written by a company, like the almost defacto-standard
eslint-airbnb. Sometimes the rules are made by standards bodies like PSR-12 by the [PHP-FIG] (https://github.com/squizlabs/PHP_CodeSniffer/tree/master/src/Standards/PSR12), and the tools create a ruleset to match, like the PSR-2 ruleset for
CodeSniffer.
Today I even had to use awesome-lint in order to make sure awesome-earth was conforming to their rules, which were built using the Remark Markdown linter.
When it comes to API descriptions, most companies of a certain size end up with a "Style Guide", "Style Book", "Design Guide", etc. These are often on a Google Doc, wiki, or some other sort of docs/content management system. I've seen loads of these, and written plenty. Many companies even publish
them.
Text-based Style Guides are a Time Suck
The trouble with these text-based documents is that they are large, terse,
unexciting documents, which developers rarely read. If developers do read them cover to cover, and remember everything in there, that knowledge becomes partially out of date when new rules are added because they won't know about them until they re-read everything cover to cover again.
At API the Docs I saw a talk from
Kelsey Lambert at Salesforce, and their style guide is an example OpenAPI
description document which they ask people to check now and then when they are working on something to get ideas of the sorts of things they should use.
Salesforce... The giant company with 238479347 APIs who maintain 40 major
versions per API, their style guide enforcement approach is eyeballing and
memory. Agh I feel for you folks! I have been here and it was bad.
No developers can be blamed for any of this mess. API developers are busy, and the folks writing style guides are just trying to figure it out as they go along. This mess is an industry problem, but thankfully tools have popped up which can enforce these same style guide concepts through automation.
- api-linter by Google
- graphql-doctor by Cap Collectif
- graphql-schema-linter by Christian Joudrey
- Spectral by Stoplight
Each one of these projects sets out to do relatively similar things, but for different types of API.
Spectral for HTTP APIs
Spectral is a JSON/YAML data linter, with built in rules for OpenAPI v2/v3 and JSON Schema.
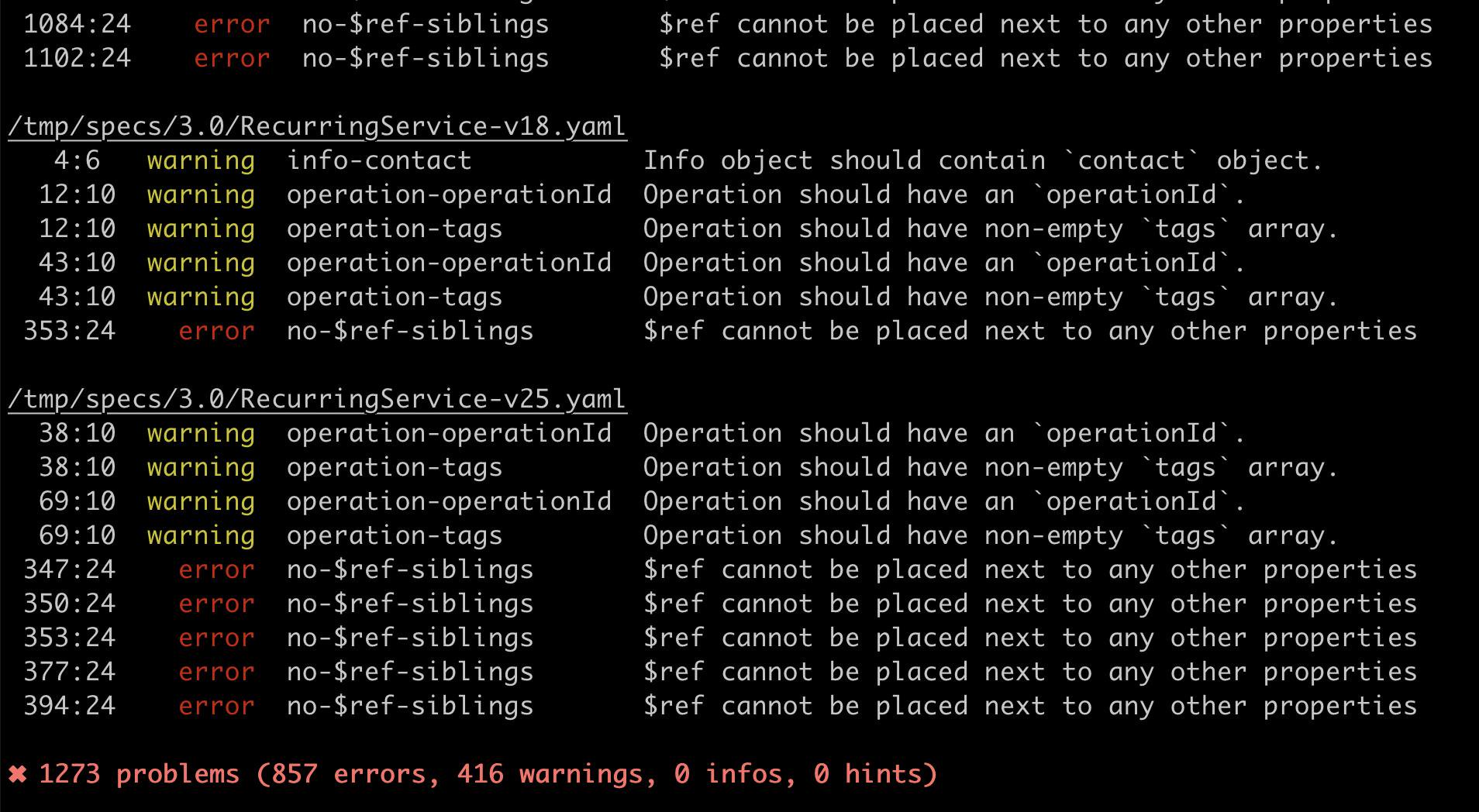
Running the default OpenAPI ruleset on the average document will find plenty of suggestions, which can be helpful for developers not entirely familiar with OpenAPI. Something as small as reminding people to add parameter-descriptions can help make human-readable docs more
useful, and they might not have even realized that was possible.
You can use Spectral to create rulesets, and these rulesets can have custom rules, and even custom functions!
These custom rules can look a bit like this:
rules:
schema-names-pascal-case:
description: Schema names MUST be written in PascalCase
message: '{{property}} is not PascalCase: {{error}}'
recommended: true
type: style
given: '$.components.schemas.*~'
then:
function: casing
functionOptions:
type: pascal
This one is a popular one. OpenAPI does not care how you capitalize your models, but a lot of code generators will use the model names for code, and having inconsistent class names will upset people.
Let's take it a step further:
rules:
paths-kebab-case:
description: Should paths be kebab-case.
message: '{{property}} is not kebab-case: {{error}}'
severity: warn
recommended: true
given: $.paths[*]~
then:
function: casing
functionOptions:
type: kebab
separator:
char: "/"
This rule is actually looking beyond the metadata of your API descriptions, and is looking at the actual API design itself. This is saying that the "paths" (endpoints) must be hyphenated, so /recent-files is good but /recent_files is not ok.
You can get really creative with regex patterns if that floats your boat.
rules:
no-x-headers:
description: "Please do not use headers with X-"
message: "Headers cannot start with X-, so please find a new name for {{property}}. More: https://tools.ietf.org/html/rfc6648"
recommended: true
given: "$..parameters.[?(@.in === 'header')].name"
then:
function: pattern
functionOptions:
notMatch: '^(x|X)-'
I don't know why but at some point during the lifecycle of any given API, some developer will suggest adding an X-Foo header, despite over a decade of it causing issues. Well, we can keep them outta here with this rule.
Done early enough, this will shape the actual API as it is being developed. If you are doing code first then ok, you have to go back and change a bunch of code. Hopefully you didn't ship it, because now you need to go and make a bunch of redirects for /recent_files /recent_files. If you use an API design first workflow, then you notice this early on when you've just got some YAML, and your API gets built right in the first place.
Seeing as Spectral is a CLI/JS tool, enforcing this style guide can be done
in all sorts of ways.
- in a git hook
- in a JS test suite
- on continuous integration to fail builds with errors
If you're using Stoplight Studio then it's baked right into the editor, so people designing APIs just do it all correctly straight away. No need to alt tab away to the CLI or wait until a PR is made.
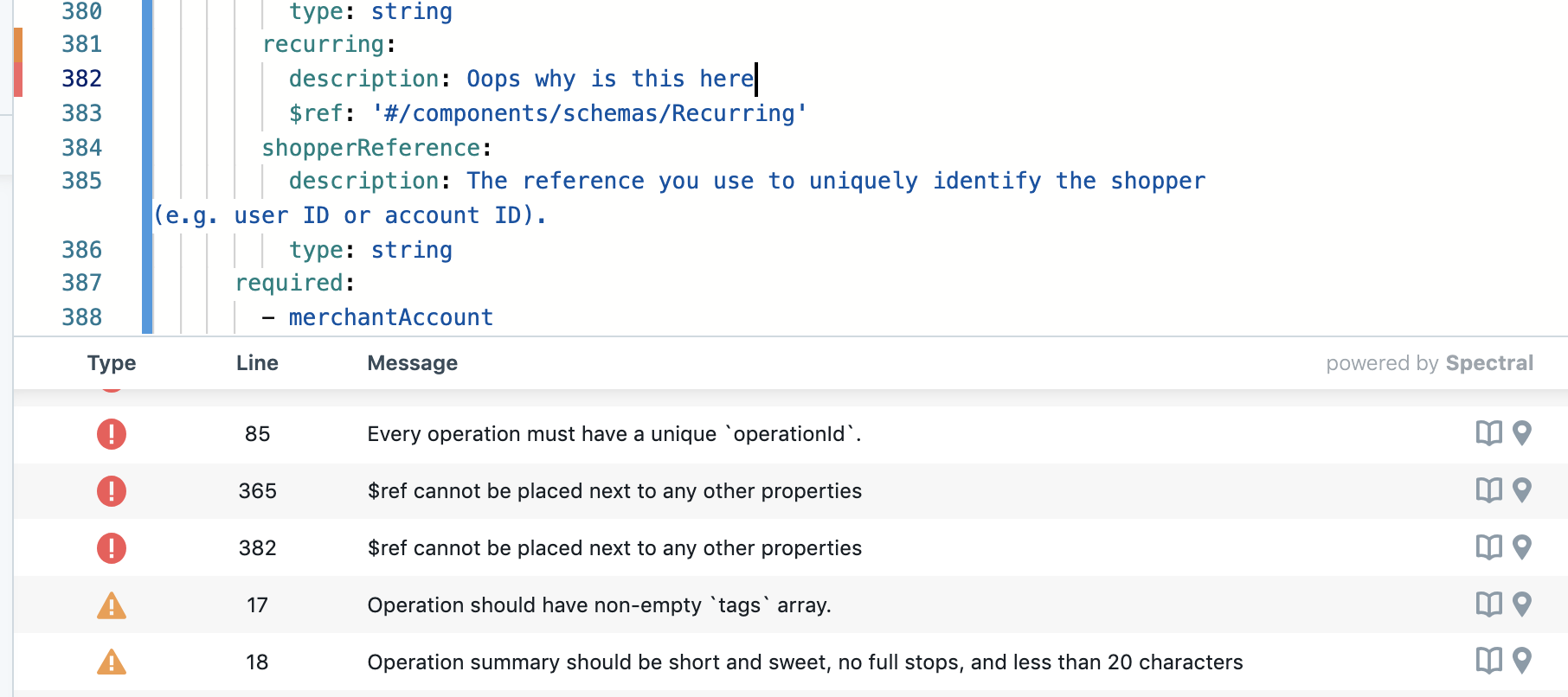
I am trying to find time to take a style guides from Heroku or PayPal and turn them into a huge example ruleset. At the very least, I can take some inspiration for a new ruleset I'm putting together: The OpenAPI Contrib > Style Guide. This should be an interesting community effort.
Spectral also has a GitHub Action and a ~GitHub Bot~ (RIP) which we are working on improving. Commenting on ranges and suggestions coming soon! 😎
GraphQL Doctor & Schema Linter
GraphQL has it's own [built-in type system] (https://graphql.org/learn/schema/), which has some of the same sort of keywords as OpenAPI / JSON Schema based stuff.
GraphQL makes some design decisions easier, like how you handle relationships. No need to pick between nesting/embedding related resources, inlining everything with a compound documents, or using hyperlinks to link to related data, GraphQL decides that for you. Still, there is a lot of inconsistency that can occur outside of the default decisions GraphQL makes. GraphQL people do not escape the need to lint, but luckily a great linter exists: GraphQL Schema Linter.
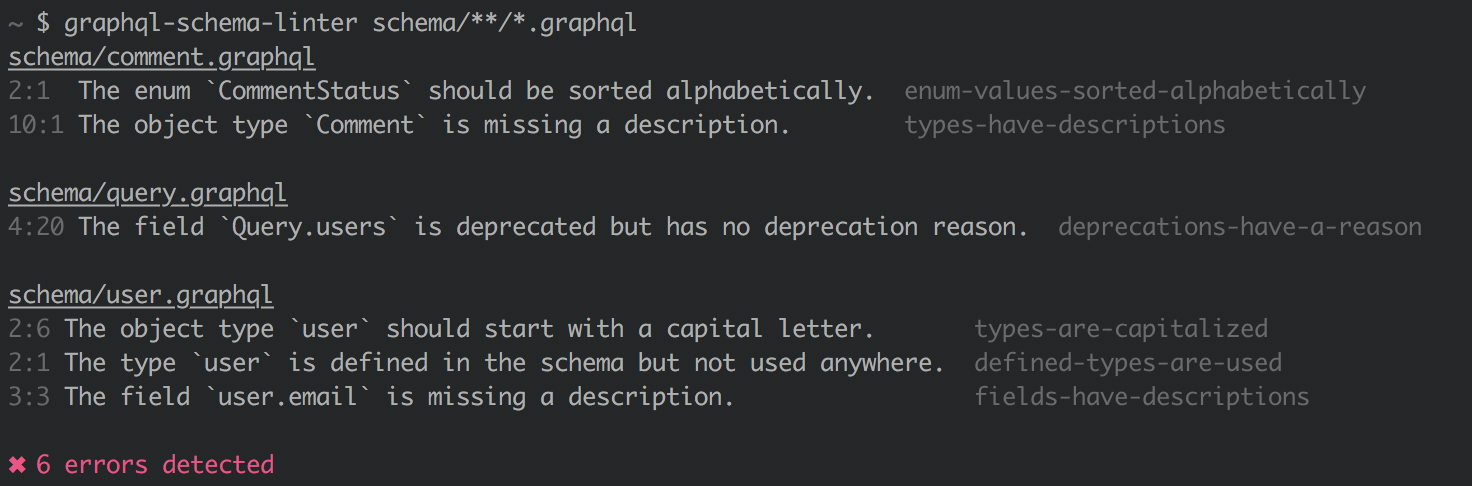
Custom rules can be written for this one too, so you can automate your style guide in CI. No bot or GitHub Action that I can see, but they aren't too tough to knock together.
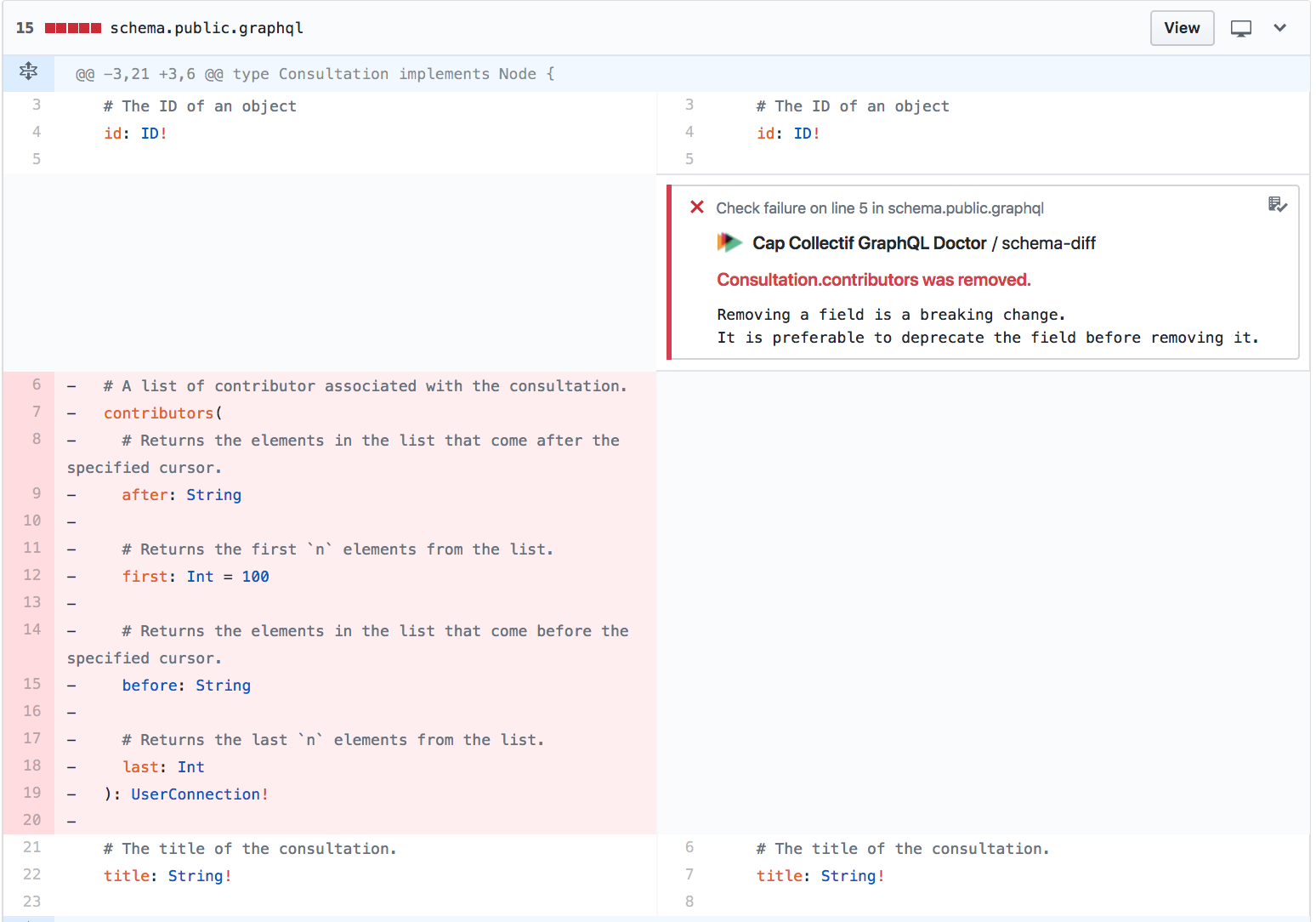
One schema tool in GraphQL land with a great bot is GraphQL Doctor. It seems
like it wants to help with a lot more linting in general, but so far it is
focused on detecting breaking changes. Like any type system, there is a fine
line between careful evolution and recklessly changing stuff, and GraphQL Doctor will spot the latter.
It would be nice to see the two tools merge, or maybe the GraphQL Doctor bot can bake in support for GraphQL Schema Linter, but for now it's a two-stop shop.
Google's "API Linter"
Google is doing some pretty interesting work in the API space. They were one of the first big players in the API space consistently explaining "Sometimes you want REST, sometimes you want RPC", and they're keeping at it with a general tool that works for gRPC and HTTP-in-general too. API linter operates on the protobuf surface layer, but can be set up to work with HTTP endpoints:
When using protocol buffers, each RPC must define the HTTP method and path using the google.api.http annotation:
rpc CreateBook(CreateBookRequest) returns (Book) {
option (google.api.http) = {
post: "/v1/{parent=publishers/*}/books/*"
body: "book"
};
}
message CreateBookRequest {
// The publisher who will publish this book.
// When using HTTP/JSON, this field is automatically populated based
// on the URI, because of the `{parent=publishers/*}` syntax.
string parent = 1;
// The book to create.
// When using HTTP/JSON, this field is populated based on the HTTP body,
// because of the `body: "book"` syntax.
Book book = 2;
// The user-specified ID for the book.
// When using HTTP/JSON, this field is populated based on a query string
// argument, such as `?book_id=foo`. This is the fallback for fields that
// are not included in either the URI or the body.
string book_id = 3;
}
The core ruleset for API Linter is rather impressive, and focuses a lot on awkward bits in the HTTP specification which are a bit unclear. Like, should GET have a body? The answer is a very squishy kinda maybe it can, but probably don't, depends on the tool you are building, ugh. Help.
Google decided to just answer that with: nope.
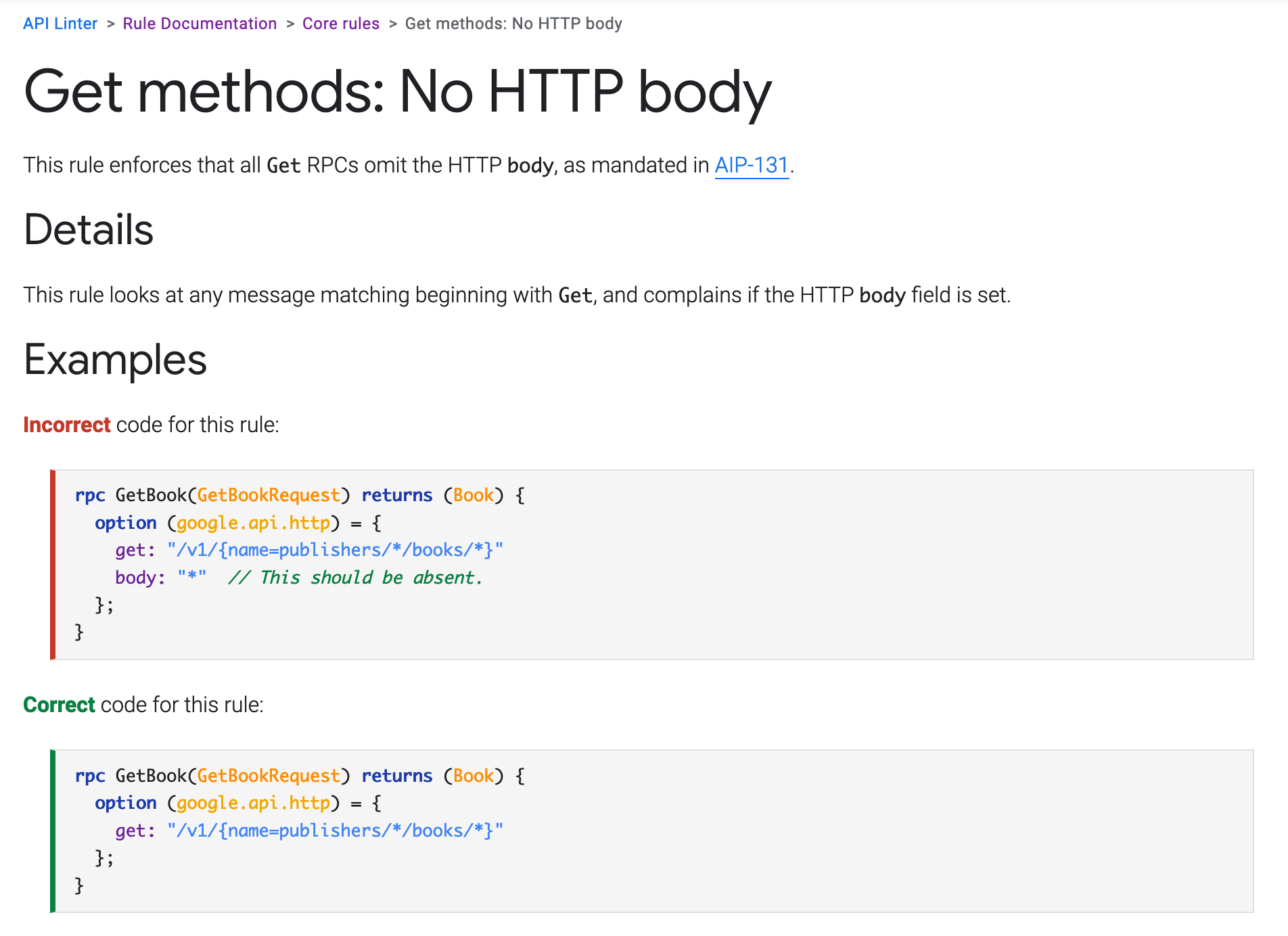
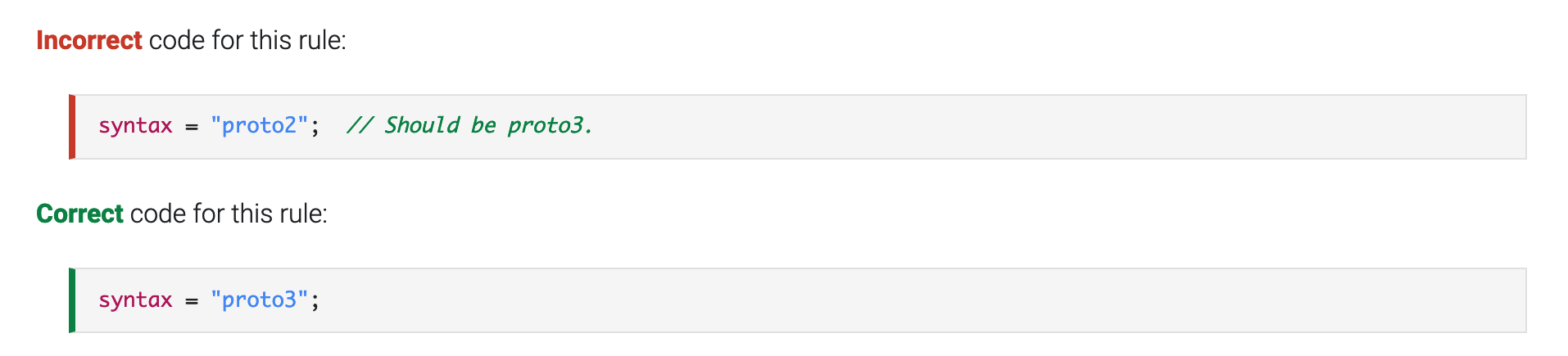
They also decided to persuade teams upgrade from proto2 to proto3.
Rule Ideas
You can automate pretty much anything with this stuff, and I've been thinking a lot of rules that go beyond the common use cases of enforcing naming or pluralization.
Security
- Ban HTTP Basic entirely
- Make sure every endpoint has some sort of security (OAuth 2, API Key, but not both)
- Every response should support
application/vnd.api+json(JSON:API) not just plain-old JSON - ID's as integers let people crawl your API incredibly easily, switch to UUID
Errors
- Your 20X response seems to have errors in it, why do you hate your consumers
- There are no URLs in your errors, how can anyone find out more information about what went wrong
- Error format should be RFC 7807
Versioning
- Keep version numbers out of the URL
- Version numbers in headers please
- Ban all versioning and demand evolution (prepare for battle)
Many of these rules are HTTP API specific but you get the idea. Over time I'll
be working on some of these and adding them to OpenAPI Contrib's Style
Guide, and if you'd like to
contribute I'll be happy to guide you through the process over on GitHub.
Summary
If you've heard the term API Governance, this is pretty much what most people are talking about. Currently a lot of the people trying to do governance are eyeballing API descriptions on every single PR, and training people to memorize all the quality rules they've come up with.
Manual API training is a thankless, inefficient, never-ending task, and it can be replaced (or drastically streamlined) with a linter baked into an editor, git hook, CI pipeline, GitHub Action, or a bot.
Don't waste customers time forcing them to try and figure out your
inconsistencies. Don't waste all API developers time learning to memorizing
style guides. Don't waste the API governance teams time reviewing APIs manually. Don't waste everyone's time fixing inconsistencies in production later.



